1. Der Anfang des Deep Learnings: Grundlegende Prinzipien und der Kontext der technologischen Evolution
Der Beginn der Erforschung der DNA des Deep Learnings
“Echte technologische Innovationen entstehen aus den Misserfolgen der Vergangenheit” - Geoffrey Hinton, Turing-Preis-Auftritt 2018
1.1 Das Ziel dieses Buches
Deep Learning ist ein Bereich des Maschinelles Lernens, der mit erstaunlichen Ergebnissen und einem schnellen Fortschritt verbunden ist. Es sind Modelle wie GPT-4 und Gemini aufgetaucht, und es gibt sowohl Erwartungen als auch Bedenken bezüglich allgemeiner künstlicher Intelligenz (AGI). Während Forschungspapiere und Technologien rasch fortschreiten, haben selbst Experten Schwierigkeiten, Schritt zu halten.
Diese Situation ist vergleichbar mit der Zeit Ende der 1980er Jahre, als PCs und Programmiersprachen populär wurden. Damals erschienen zahlreiche Technologien, doch am Ende bildeten nur wenige Kerntechnologien die Grundlage des modernen Computings. Ähnlich wie damals werden auch heute unter den verschiedenen Deep-Learning-Architekturen wie Neuronalen Netzen, CNNs, RNNs, Transformatoren, Diffusion und Multimodalitäten nur wenige, die ein wesentliches DNA-Element teilen, das Fundament der KI bilden und weiterhin entwickelt werden.
Dieses Buch beginnt aus dieser Perspektive. Es konzentriert sich weniger auf einfache API-Nutzung, grundlegende Theorien oder Beispiele und analysiert stattdessen die DNA des technologischen Fortschritts. Vom McCulloch-Pitts-Neuronenmodell von 1943 bis zur neuesten Multimodalarchitektur von 2025, als ob es sich um einen Evolutionsprozess handelt, fokussiert es sich auf den Hintergrund, die zu lösenden wesentlichen Probleme und die Verbindung zu vorherigen Technologien. Es zeichnet also eine Art Stammbaum der Deep-Learning-Technologie auf. In Abschnitt 1.2 wird dieser Inhalt kurz zusammengefasst.
Zu diesem Zweck hat dieses Buch folgende Merkmale:
Erklärung aus DNA-Perspektive: Es geht nicht nur um die Aufzählung von Technologien, sondern darum, warum jede Technologie entstanden ist, welches Problem sie lösen sollte und in welcher Beziehung sie zu früheren Technologien steht, also das technologische Phylogenie.
Knappe aber tiefschürfende Erklärungen: Es hilft dabei, Kernkonzepte und Prinzipien klar zu verstehen, ohne unnötige Details aufzunehmen.
Berücksichtigung neuester technologischer Entwicklungen: Es umfasst die neuesten Technologien bis 2025 (z. B. Retentive Networks, Mixture of Experts, Multimodal Models) und behandelt den vordersten Bereich der Deep-Learning-Entwicklung.
Brücke zwischen Praxis und Forschung: Es bietet eine ausgewogene Darstellung von praktischen Codebeispielen und mathematischer Intuition, um Theorie und Praxis zu verbinden.
Erweiterte Beispiele: Nicht nur funktionierende Codes, sondern auch entwickelte Beispiele, die sofort in Forschung oder Entwicklung angewendet werden können.
Dadurch soll sowohl Praktikern als auch Forschern bei der Erhöhung ihrer Expertise geholfen werden. Zudem sollen ethische und soziale Auswirkungen von KI-Technologien sowie Überlegungen zur technologischen Demokratisierung ebenfalls thematisiert werden.
1.2 Geschichte des Deep Learnings
Herausforderung: Wie kann man Maschinen dazu bringen, wie Menschen zu denken und zu lernen?
Forscherfrust: Das Nachahmen der komplexen Funktionsweise des menschlichen Gehirns war eine extrem schwierige Aufgabe. Frühe Forscher hingen von einfachen regelbasierten Systemen oder begrenzten Wissensdatenbanken ab, was jedoch die Vielfalt und Komplexität der realen Welt nur unzureichend verarbeitete. Um ein wirklich intelligentes System zu schaffen, war es notwendig, dass es aus Daten lernen, komplexe Muster erkennen und abstrakte Konzepte verstehen konnte. Die Implementierung dieser Fähigkeiten stellte den Kern der Herausforderung dar.
Die Geschichte des Deep Learnings begann 1943 mit Warren McCulloch und Walter Pitts, die das McCulloch-Pitts-Neuron, ein mathematisches Modell zur Erklärung der Funktionsweise von Neuronen, präsentierten. Dies definierte die grundlegenden Bestandteile von neuronalen Netzen. 1949 stellte Donald Hebb das Hebb’sche Lernen vor und erläuterte so das Grundprinzip des Anpassens der Synapsengewichte, also des Lernens. 1958 war Franks Rosenblatts Perzeptron das erste praktische neuronale Netz, stieß jedoch an die Grenzen bei nicht-linearen Klassifizierungen wie dem XOR-Problem.
Die 1980er Jahre brachten wichtige Durchbrüche. 1980 schlug Kunihiko Fukushima den Neocognitron (Grundlage des Faltungsprinzips) vor, der später die Kernidee für CNNs wurde. Der wichtigste Fortschritt war die Entwicklung des Rückpropagationsalgorithmus im Jahr 1986 durch Geoffrey Hinton und sein Team. Dieser Algorithmus ermöglichte das effektive Lernen in mehrschichtigen neuronalen Netzen und etablierte sich als Kern des neuronale Netzwerklernens. 2006 schlug Hinton den Begriff “Deep Learning” vor, was einen neuen Meilenstein markierte.
Seither wuchs Deep Learning dank der Entwicklung von großen Datenmengen und Rechenleistung stark. 2012 gewann AlexNet bei der ImageNet-Konkurrenz mit überlegener Leistung und bewies die Praktikabilität des Deep Learnings. Danach kamen innovative Architekturen wie LSTM (1997) aus der Familie der Recurrent Networks und das Attention-Mechanismus (2014) zum Einsatz. Besonders 2017s Transformer von Google revolutionierte die Paradigmen der natürlichen Sprachverarbeitung. Durch Self-Attention wurden die einzelnen Teile einer Eingabe-Sequenz direkt miteinander verbunden, was das Problem langer Abhängigkeiten löste.
Auf Basis des Transformers entstanden BERT und die GPT-Reihe, wodurch die Leistung der Sprachmodelle sprunghaft verbessert wurde. 2021 kam der Vision Transformer (ViT) hinzu, durch den sich der Transformer erfolgreich auf Bildverarbeitung anwenden ließ und die Entwicklung von Multimodal Learning beschleunigte.
Kürzlich erhöhen riesige Sprachmodelle wie GPT-4 und Gemini die Erwartungen bezüglich der Realisierbarkeit von AGI. Diese nutzen fortgeschrittene Architekturen wie Retentive Networks (2023), Effizienztechnologien wie FlashAttention (nach 2023) und Techniken wie Mixture of Experts (MoE) (2024), um noch raffinierter zu werden. Darüber hinaus entwickeln sich Multimodal-Modelle, die verschiedene Formen von Daten wie Text, Bild und Audio integriert verarbeiten können (z.B., Gemini Ultra 2.0 im Jahr 2024 und Gemini 2.0 im Jahr 2025), was über einfache Frage-Antwort-Szenarien hinausgehende hochwertige kognitive Fähigkeiten wie Inferenz, Kreativität und Problemlösung ermöglicht.
Die Entwicklung des Deep Learnings basiert auf folgenden Kernkomponenten. 1. Erhöhung der Verfügbarkeit von großen Datenmengen 2. Entwicklung von Hochleistungsrechenressourcen wie GPUs 3. Entwicklung effizienter Lernalgorithmen und Architekturen, wie Backpropagation, Attention, Transformer sowie Core Architecture, Generative Models
Diese Fortschritte setzen sich fort, es gibt jedoch immer noch Herausforderungen zu meistern. Die Erklärbarkeit von Modellen (Interpretability), die Daten-effiziente Arbeit, der Energieverbrauch und die Weiterentwicklung von Efficiency & Advanced Concepts sind wichtige Aufgaben.
Im Folgenden ist ein technisches DNA-Stammbaum zur Visualisierung dargestellt.
Nachdem Warren McCulloch und Walter Pitts 1943 ihr Modell des künstlichen Neurons (McCulloch-Pitts-Neuron) vorgestellt hatten, stellte der kanadische Psychologe Donald O. Hebb 1949 in seinem Buch “The Organization of Behavior” die grundlegenden Prinzipien des neuronalen Lernens vor. Dieses Prinzip wird als Hebbsche Regel (Hebb’s Rule) oder Hebbian Learning bezeichnet und hat erheblichen Einfluss auf die Forschung zu künstlichen Neuronen, einschließlich Deep Learning, gehabt.
1.3.1 Hebbian Learning Regel
Der Kerngedanke des Hebbian Learnings ist sehr einfach. Wenn zwei Neuronen gleichzeitig oder wiederholt aktiviert werden, dann erhöht sich die Stärke ihrer Verbindung. Umgekehrt, wenn zwei Neuronen zu unterschiedlichen Zeiten aktiviert werden oder ein Neuron aktiv und das andere inaktiv bleibt, verringert sich die Verbindungsstärke oder verschwindet.
Dies kann mathematisch wie folgt ausgedrückt werden:
\[
\Delta w_{ij} = \eta \cdot x_i \cdot y_j
\]
Dabei gilt:
\(\Delta w_{ij}\) ist die Änderung der Verbindungsstärke (Gewicht) zwischen Neuron \(i\) und Neuron \(j\).
\(\eta\) ist die Lernrate (learning rate), eine Konstante, die den Umfang der Veränderung der Verbindungskraft steuert.
\(x_i\) ist der Aktivierungswert (Eingabe) von Neuron \(i\).
\(y_j\) ist der Aktivierungswert (Ausgabe) von Neuron \(j\).
Diese Gleichung zeigt, dass die Verbindungsstärke zunimmt (\(\Delta w_{ij}\) positiv), wenn beide Neuronen aktiv sind (\(x_i\) und \(y_j\) beide positiv). Umgekehrt, wenn nur eines der beiden Neuronen aktiv ist oder beide inaktiv bleiben, verringert sich die Verbindungskraft oder bleibt unverändert. Hebbian Learning ist eine der frühen Formen des nichtüberwachten Lernens (unsupervised learning). Das bedeutet, dass das neuronale Netzwerk ohne vorgegebene Lösungen (Labels) aus den Mustern in den Eingabedaten lernt und die Verbindungskräfte selbst anpasst.
1.3.2 Beziehung zur Gehirnplastizität
Hebbian Learning geht über eine einfache mathematische Regel hinaus und bietet wichtige Einblicke in die Funktionsweise des menschlichen Gehirns. Das Gehirn verändert sich ständig durch Erfahrungen und Lernen, was als Gehirnplastizität (brain plasticity) oder neuronale Plastizität (neural plasticity) bezeichnet wird. Hebbian Learning spielt eine zentrale Rolle bei der Erklärung von synaptischer Plastizität (synaptic plasticity), einer Form der neuronalen Plastizität. Synapsen sind die Verbindungspunkte zwischen Neuronen und entscheiden über die Effizienz der Informationsübertragung. Hebbian Learning verdeutlicht das grundlegende Prinzip der synaptischen Plastizität, nämlich dass “Neuronen, die zusammen aktiviert werden, auch zusammen verbindet sind”. Langfristige Potenzierung (Long-Term Potentiation, LTP) und langfristige Depression (Long-Term Depression, LTD) sind wichtige Beispiele für synaptische Plastizität. LTP beschreibt das Phänomen der Stärkung von Synapsenverbindungen gemäß der Hebbschen Regel, während LTD das entgegengesetzte Phänomen darstellt. LTP und LTD spielen eine entscheidende Rolle beim Lernen, Gedächtnis und der Entwicklung des Gehirns.
1.4 Neuronale Netze (NN, Neural Network)
Neuronale Netze sind Funktionen-Approximatoren, die Eingaben entgegennehmen und Werte erzeugen, die möglichst nahe am gewünschten Ausgang liegen. Mathematisch wird dies durch \(f_\theta\) dargestellt, wobei \(f\) die Funktion und \(\theta\) die Parameter darstellen, die aus Gewichten (weight) und Bias bestehen. Der Kern von neuronalen Netzen liegt darin, dass sie in der Lage sind, diese Parameter automatisch auf Basis von Daten zu lernen.
Das erste neuronale Netz wurde 1944 von Warren McCullough und Walter Pitts vorgeschlagen und war von biologischen Neuronen inspiriert. Moderne neuronale Netze sind jedoch reine mathematische Modelle. In der Tat sind neuronale Netze leistungsstarke mathematische Werkzeuge, die in der Lage sind, stetige Funktionen zu approximieren, wie durch den Universal Approximation Theorem bewiesen wurde.
1.4.1 Grundstruktur von neuronalen Netzen
Neuronale Netze haben eine hierarchische Struktur, die aus Eingangsschicht, verborgenen Schichten und Ausgangsschicht besteht. Jede Schicht besteht aus Knoten (Neuronen), die miteinander verbunden sind, um Informationen weiterzuleiten. Im Grunde bestehen neuronale Netze aus einer Kombination von linearen Transformationen und nichtlinearen Aktivierungsfunktionen.
Mathematisch gesehen führt jede Schicht eines neuronalen Netzwerks eine lineare Transformation wie folgt durch:
\[ y = Wx + b \]
Dabei sind:
\(x\) der Eingabevektor
\(W\) die Gewichtsmatrix
\(b\) der Biasvektor
\(y\) der Ausgabevektor
Diese Struktur mag einfach erscheinen, aber ein neuronales Netz mit ausreichend Neuronen und Schichten kann jede stetige Funktion mit beliebiger Genauigkeit approximieren. Dies ist der Grund, warum neuronale Netze in der Lage sind, komplexe Muster zu lernen und eine Vielzahl von Problemen zu lösen.
Klicken Sie hier, um den Inhalt anzuzeigen (Deep Dive: Universal Approximation Theorem)
Universelle Approximationssatz
Herausforderung: Wie kann man beweisen, dass neuronale Netze tatsächlich jede beliebig komplexe Funktion approximieren können?
Forscherfrust: Obwohl neuronale Netze viele Schichten und Neuronen haben können, war es nicht offensichtlich, ob sie tatsächlich jede stetige Funktion darstellen können. Es gab Bedenken, dass sie nur die Kombination einfacher linearer Transformationen sind, die möglicherweise nicht ausreichen, um komplexe Nichtlinearitäten zu repräsentieren. Die Abhängigkeit von rein empirischen Ergebnissen ohne theoretische Garantien war ein großes Hindernis für die Entwicklung der neuronalen Netzforschung.
Der Universelle Approximationssatz ist eine zentrale Theorie, die die starke Darstellungskraft von neuronalen Netzen stützt. Dieser Satz beweist, dass ein ein-schichtiges neuronales Netz mit ausreichend breiter verborgener Schicht jede beliebige stetige Funktion mit der gewünschten Genauigkeit approximieren kann.
Kernideen:
Nichtlineare Aktivierungsfunktionen: Nichtlineare Aktivierungsfunktionen wie ReLU, Sigmoid und tanh sind ein wesentlicher Bestandteil, der es neuronalen Netzen ermöglicht, Nichtlinearitäten darzustellen. Ohne diese Aktivierungsfunktionen wären beliebig viele Schichten nur die Kombination linearer Transformationen.
Ausreichend breite verborgene Schicht: Wenn eine verborgene Schicht ausreichend viele Neuronen hat, besitzt das neuronale Netz die “Flexibilität”, um beliebige komplexe Funktionen darzustellen. Ähnlich wie es möglich ist, mit genügend vielen Teilen ein Mosaikbild in jeder gewünschten Form zu erstellen.
Mathematische Darstellung:
Satz (Universeller Approximationssatz):
Sei \(f : K \rightarrow \mathbb{R}\) eine beliebige stetige Funktion, die auf einer beschränkten abgeschlossenen Menge (compact set) \(K \subset \mathbb{R}^d\) definiert ist. Für jedes gegebene Fehlerlimit \(\epsilon > 0\) existiert ein ein-schichtiges neuronales Netz\(F(x)\), das die folgende Bedingung erfüllt.
\(|f(x) - F(x)| < \epsilon\), für alle \(x \in K\).
Hier hat \(F(x)\) die folgende Form:
\(F(x) = \sum_{i=1}^{N} w_i \cdot \sigma(v_i^T x + b_i)\)
Ausführliche Erklärung:
\(f : K \rightarrow \mathbb{R}\):
\(f\) ist die zu approximierende Zielfunktion (target function).
\(K\) ist das Definitionsbereich (domain) der Funktion, eine beschränkte abgeschlossene Menge (compact set) in \(\mathbb{R}^d\) (d-dimensionalen reellen Raum). In praktischen Situationen stellt dies oft keine große Einschränkung dar, da die meisten realen Eingabedaten einen begrenzten Bereich haben.
\(\mathbb{R}\) ist die Menge der reellen Zahlen. Die Funktion \(f\) ordnet jedem Punkt in \(K\) (\(x\)) einen reellen Wert (\(f(x)\)) zu. (Für mehrdimensionale Funktionen und mehrere Ausgänge siehe unten.)
\(\epsilon > 0\): Ein beliebiger positiver Wert, der die Genauigkeit der Approximation darstellt. Je kleiner \(\epsilon\) ist, desto genauer ist die Approximation.
\(|f(x) - F(x)| < \epsilon\): Für alle \(x \in K\), bedeutet dies, dass der Unterschied zwischen dem tatsächlichen Funktionswert \(f(x)\) und dem Output des neuronalen Netzes \(F(x)\) kleiner als \(\epsilon\) ist. Dies zeigt, dass das neuronale Netz die Funktion \(f\) innerhalb eines Fehlerbereichs von \(\epsilon\) approximieren kann.
\(F(x) = \sum_{i=1}^{N} w_i \cdot \sigma(v_i^T x + b_i)\): Dies repräsentiert die Struktur eines ein-schichtigen neuronalen Netzes.
Das universelle Approximationstheorem garantiert, dass ein einschichtiges Neuronales Netz mit einer ausreichend breiten verdeckten Schicht, eine beliebige stetige Funktion, die auf einer beschränkten abgeschlossenen Menge definiert ist, mit gewünschter Genauigkeit approximieren kann. Die Aktivierungsfunktion muss nichtpolynomiell sein. Dies bedeutet, dass neuronale Netze eine sehr starke Darstellungskraft (representational power) besitzen und sie die theoretische Grundlage für Deep Learning bilden. Barrons Theorem liefert Einblicke in die Konvergenzgeschwindigkeit des Fehlers.
Wichtige Punkte
Existenzbeweis: Das universelle Approximationstheorem ist ein Existenzbeweis und legt keinen Lernalgorithmus vor. Es garantiert, dass solche neuronale Netze existieren, aber wie man sie tatsächlich findet, ist eine separate Frage (Rückwärtspropagation und Gradientenabstieg sind Methoden, die dieses Problem lösen).
Einschichtig vs. Mehrschichtig: In der Praxis sind mehrstufige Neuronale Netze (Deep Neural Networks) oft effizienter und haben bessere Verallgemeinerungseigenschaften als einschichtige neuronale Netze. Obwohl das universelle Approximationstheorem die theoretische Grundlage für Deep Learning bildet, ist der Erfolg von Deep Learning das Ergebnis einer Kombination aus mehrstufiger Struktur, speziellen Architekturen und effizienten Lernalgorithmen. Einschichtige neuronale Netze können theoriegemäß alles darstellen, sind aber in der Praxis viel schwieriger zu trainieren.
Bewusstsein der Grenzen: Das universelle Approximationstheorem ist eine starke Aussage, garantiert jedoch nicht, dass alle Funktionen effizient approximiert werden können. Wie Gegenbeispiele zeigen, können bestimmte Funktionen die Approximation von sehr vielen Neuronen erfordern.
Referenzen:
Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals, and Systems, 2(4), 303-314. (Initiales universelles Approximationstheorem für Sigmoid-Aktivierungsfunktionen)
Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks, 2(5), 359-366. (Universelles Approximationstheorem für allgemeinere Aktivierungsfunktionen)
Barron, A. R. (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information Theory, 39(3), 930-945. (Barrons Theorem zur Konvergenzgeschwindigkeit des Fehlers)
Pinkus, A. (1999). Approximation theory of the MLP model in neural networks. Acta Numerica, 8, 143-195. (Tiefere Überprüfung des universellen Approximationstheorems)
Goodfellow, I., Bengio, Y., & Courville, A. (2016).Deep Learning. MIT Press. (Kapitel 6.4: Deep-Learning-Lehrbuch, enthält Inhalte zum universellen Approximationstheorem)
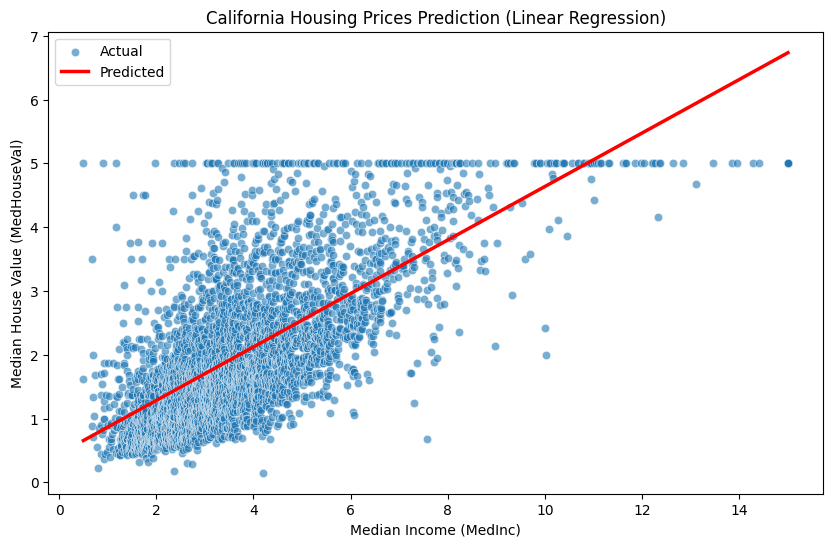
1.4.2 Vorhersage von Hauspreisen mit linearen Approximatoren (linear approximator)
Um die grundlegenden Konzepte eines neuronalen Netzes zu verstehen, betrachten wir ein einfaches lineares Regressionsproblem (Linear Regression). Hierfür verwenden wir den California Housing-Datensatz aus der scikit-learn-Bibliothek. Dieser Datensatz enthält verschiedene Merkmale (features) von Häusern und kann verwendet werden, um ein Modell zu erstellen, das Hauspreise vorhersagt. Als einfaches Beispiel nehmen wir an, dass der Hauspreis nur von einem Merkmal, dem mittleren Einkommen (MedInc), bestimmt wird, und implementieren einen linearen Approximator.
Code
import numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.datasets import fetch_california_housingfrom sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split# Load the California housing datasethousing = fetch_california_housing(as_frame=True)data = housing.frame# Use only Median Income (MedInc) and Median House Value (MedHouseVal)data = data[["MedInc", "MedHouseVal"]]# Display the first 5 rows of the dataprint(data.head())# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split( data[["MedInc"]], data["MedHouseVal"], test_size=0.2, random_state=42)# Create and train a linear regression modelmodel = LinearRegression()model.fit(X_train, y_train)# Make predictions on the test datay_pred = model.predict(X_test)# Prepare data for visualizationplot_data = pd.DataFrame({'MedInc': X_test['MedInc'], 'MedHouseVal': y_test, 'Predicted': y_pred})# Sort for better line plot visualization. Crucially, sort *after* prediction.plot_data = plot_data.sort_values(by='MedInc')# Visualize using Seabornplt.figure(figsize=(10, 6))sns.scatterplot(x='MedInc', y='MedHouseVal', data=plot_data, label='Actual', alpha=0.6)sns.lineplot(x='MedInc', y='Predicted', data=plot_data, color='red', label='Predicted', linewidth=2.5)plt.title('California Housing Prices Prediction (Linear Regression)')plt.xlabel('Median Income (MedInc)')plt.ylabel('Median House Value (MedHouseVal)')plt.legend()plt.show()# Print the trained weight (coefficient) and bias (intercept)print("Weight (Coefficient):", model.coef_[0])print("Bias (Intercept):", model.intercept_)
Der obige Code lädt zunächst den Datensatz der Kalifornischen Hauspreise mit der Funktion fetch_california_housing. Nach dem Laden der Daten als Pandas DataFrame mit as_frame=True, werden nur die Merkmale des Hauspreises (MedHouseVal) und das mittlere Einkommen (MedInc) ausgewählt. Anschließend wird der Datensatz in Trainings- und Testsets unter Verwendung der Funktion train_test_split aufgeteilt, und ein lineares Regressionsmodell mit der Klasse LinearRegression erstellt. Das Modell wird mit den Trainingsdaten durch die Methode fit trainiert. Mit der Methode predict werden Vorhersagen für die Testdaten durchgeführt, und die tatsächlichen Werte sowie die Vorhersagen werden mithilfe von Seaborn visualisiert. Schließlich werden die Gewichte und der Bias des trainierten Modells ausgegeben.
So ist auch mit einer einfachen linearen Transformation eine gewisse Vorhersagegenauigkeit möglich. Neuronale Netze ergänzen hier nichtlineare Aktivierungsfunktionen und stapeln mehrere Schichten, um viel komplexere Funktionen zu approximieren.
1.4.3 Der Weg zu neuronalen Netzen: Prozess der Matrixoperationen
Die Vorstufe eines neuronalen Netzes ist ein linearer Approximator. Hier untersuchen wir detailliert, wie das vorherige Beispiel die tatsächlichen Werte erreicht. Die einfachste lineare Formel für die tatsächlichen Werte \(\boldsymbol y\) lautet \(\boldsymbol y = \boldsymbol x \boldsymbol W + \boldsymbol b\).
Hierbei ist \(\boldsymbol W\) das Gewicht (weight parameter) und \(\boldsymbol b\) der Bias. Das Kernstück des Lernprozesses von neuronalen Netzen besteht darin, diese beiden Parameter anhand der Daten zu optimieren. Wie in Abschnitt 1.4 gezeigt wird, fügen neuronale Netzwerke Aktivierungsfunktionen zu linearen Transformationen hinzu, um Nichtlinearität einzuführen und durch Rückwärtspropagation die Parameter zu optimieren. Hier untersuchen wir nur den einfachen Berechnungsprozess von linearen Transformationen und Rückwärtspropagation.
Zunächst werden die Parameter mit zufälligen Werten initialisiert.
Hierbei stellt \(\hat{\boldsymbol y}\) die vorhergesagten Werte dar. Der Unterschied (Loss) zwischen den tatsächlichen und vorhergesagten Werten lautet:
Die Parameteroptimierung erfolgt mit Hilfe des Gradienten (gradient). Da der Gradient in die Richtung zeigt, in die der Fehler zunimmt, wird dieser vom aktuellen Parameter abgezogen, um den Fehler zu reduzieren. Die Einführung einer Lernrate (\(\eta\)) ergibt:
Der Bias wird auf die gleiche Weise aktualisiert. Dieser Prozess der Vorwärts- (forward) und Rückwärtsrechnung (backward) wird wiederholt, um die Parameter zu optimieren, was den Lernprozess von neuronalen Netzen darstellt.
1.3.4 Implementierung mit NumPy
Wir untersuchen nun die Implementierung eines linearen Approximators mit NumPy. Zunächst bereiten wir die Eingangsdaten und die Zielwerte vor.
Code
import numpy as np# Set input values and target valuesX = np.array([[1.5, 1], [2.4, 2], [3.5, 3]])y = np.array([2.1, 4.2, 5.9])learning_rate =0.01# Adding the learning_rate variable here, even though it's unused, for consistency.print("X =", X)print("y =", y)
X = [[1.5 1. ]
[2.4 2. ]
[3.5 3. ]]
y = [2.1 4.2 5.9]
Die Lernrate wurde auf 0.01 gesetzt. Die Lernrate ist ein Hyperparameter, der die Geschwindigkeit und Stabilität des Modelllernprozesses beeinflusst. Gewichte und Bias werden initialisiert.
Code
m, n = X.shape# Initialize weights and biasweights = np.array([0.1, 0.1])bias =0.0# Corrected: Bias should be a single scalar value.print("X.shape =", X.shape)print("Initial weights =", weights)print("Initial bias =", bias)
Die vorwärts gerichtete Berechnung führt eine lineare Transformation durch. Die Formel dafür lautet wie folgt. \[ \boldsymbol y = \boldsymbol X \boldsymbol W + \boldsymbol b \]
Ich habe den Verlust berechnet. Der nächste Schritt besteht darin, die Gradienten aus dem Verlust zu berechnen. Wie machen wir das? Die Gradienten der Gewichte und des Bias lauten wie folgt:
\(\nabla_w = -\frac{2}{m}\mathbf{X}^T\mathbf{e}\)
\(\nabla_b = -\frac{2}{m}\mathbf{e}\)
Hierbei ist \(\mathbf{e}\) der Fehlervektor. Sobald wir die Gradienten berechnet haben, subtrahieren wir diese von den aktuellen Parametern, um die aktualisierten neuen Parameterwerte zu erhalten.
Code
weights_gradient =-2/m * np.dot(X.T, error)bias_gradient =-2/m * error.sum() # Corrected: Sum the errors for bias gradientweights -= learning_rate * weights_gradientbias -= learning_rate * bias_gradientprint("Updated weights =", weights)print("Updated bias =", bias)
Die obigen Schritte sind die Rückwärts- (backward) Berechnung. Sie wird auch als Rückprogagation bezeichnet, weil die Gradienten in umgekehrter Reihenfolge sequenziell berechnet werden. Jetzt implementieren wir den gesamten Trainingsprozess als Funktion.
Code
def train(X: np.ndarray, y: np.ndarray, lr: float, iters: int=100, verbose: bool=False) ->tuple:"""Linear regression training function. Args: X: Input data, shape (m, n) y: Target values, shape (m,) lr: Learning rate iters: Number of iterations verbose: Whether to print intermediate steps Returns: Tuple: Trained weights and bias """ m, n = X.shape weights = np.array([0.1, 0.1]) bias =0.0# Corrected: Bias should be a scalarfor i inrange(iters):# Forward pass y_predicted = np.dot(X, weights) + bias error = y - y_predicted# Backward pass weights_gradient =-2/m * np.dot(X.T, error) bias_gradient =-2/m * error weights -= lr * weights_gradient bias -= lr * bias_gradientif verbose:print(f"Iteration {i+1}:")print("Weights gradient =", weights_gradient)print("Bias gradient =", bias_gradient)print("Updated weights =", weights)print("Updated bias =", bias)return weights, bias
Trainiertes Modell testen.
Code
# Train the modelweights, bias = train(X, y, learning_rate, iters=2000)print("Trained weights:", weights)print("Trained bias:", bias)# Test predictionstest_X = np.array([[1.5, 1], [2.4, 2], [3.5, 3]])test_y = np.dot(test_X, weights) + biasprint("Predictions:", test_y)
Bei 50 Wiederholungen ist deutlich zu sehen, dass der Vorhersagefehler ziemlich groß ist. Ein weiterer Punkt, den wir betrachten sollten, ist die Lernrate. Warum multiplizieren wir den Gradienten mit einem sehr kleinen Wert? Ich werde eine einzelne Wiederholung durchführen und die berechneten Parameterwerte ausgeben.
Code
num_iters =1weights, bias = train(X, y, learning_rate, iters=num_iters, verbose=True)
Durch den Vergleich der durch 1000 Wiederholungen des Trainings erzielten trainierten Gewichte und Bias-Werte kann man erkennen, dass die Gradientenwerte sehr hoch sind. Wenn die Lernrate nicht verwendet wird, um die Gradientenwerte stark zu reduzieren, werden die Parameter den Fehler nicht minimieren und stattdessen weiterhin schwingen. Es wird empfohlen, eine große Lernrate zu testen.
Was unterscheidet diesen ‘linearen Approximator’ von einem neuronalen Netz-Approximator? Der Unterschied besteht in einem Punkt: Nach der linearen Berechnung werden die Werte durch eine Aktivierungsfunktion (activation function) geschickt. Mathematisch kann dies wie folgt ausgedrückt werden:
\[ \boldsymbol y = f_{active} ( \boldsymbol x \boldsymbol W + \boldsymbol b ) \]
Die Implementierung in Code ist einfach. Es gibt verschiedene Arten von Aktivierungsfunktionen, und wenn man die tanh-Funktion verwendet, sieht es so aus.
Code
y_predicted = np.tanh(np.dot(X, weights) + bias)
Neuronale Netze drücken jeden Schritt, der lineare Transformationen und die Anwendung von Aktivierungsfunktionen beinhaltet, gewöhnlich durch das Konzept einer Schicht (Layer) aus. Deshalb wird die Implementierung in zwei Schritten, wie unten dargestellt, als besser geeignet für die Darstellung von Schichten und daher bevorzugt.
Code
out_1 = np.dot(X, weights) + bias # First layery_predicted = np.tanh(out_1) # Second layer (activation)
Klicken Sie hier, um den Inhalt anzuzeigen (Tiefenblick: Theorie der kortikalen Plastizität)
Theorie der kortikalen Plastizität (Cortical Plasticity Theory)
Mountcastles Theorie der kortikalen Plastizität
Vernon Mountcastle ist ein Wissenschaftler, der im letzten Drittel des 20. Jahrhunderts bedeutende Beiträge zum Bereich der Neurowissenschaften geleistet hat, insbesondere durch seine Forschung zur funktionalen Organisation der Großhirnrinde. Ein wesentlicher Beitrag von Mountcastle war die Entdeckung der säulenförmigen Organisation (Columnar Organization). Er zeigte, dass die Großhirnrinde in vertikale Säulen organisiert ist und Neuronen innerhalb derselben Säule auf ähnliche Reize reagieren.
Mountcastles Theorie bietet einen wichtigen Grundstein für das Verständnis der kortikalen Plastizität. Seine Theorie besagt:
Säulen als funktionale Einheiten: Die Großhirnrinde besteht aus Säulen, die grundlegende funktionale Einheiten darstellen. Jede Säule enthält eine Gruppe von Neuronen, die auf bestimmte sensorische Modalitäten oder spezifische Bewegungsmuster reagieren.
Plastizität der Säulen: Die Struktur und Funktion der Säulen kann sich durch Erfahrung ändern. Wiederholte Aussetzung gegenüber bestimmten Reizen kann die Größe der Säulen, die diese Reize verarbeiten, erhöhen oder ihre Responsivität verstärken. Umgekehrt können Fehlen von Reizen die Größe der Säulen verringern oder ihre Responsivität schwächen.
Wettbewerbsinteraktionen: Nachbarschaftliche Säulen interagieren gegenseitig wettbewerblich. Eine Erhöhung der Aktivität einer Säule kann die Aktivität anderer Säulen hemmen und damit als grundlegendes Mechanismus für kortikale Reorganisation nach Erfahrungen wirken. Zum Beispiel kann häufige Nutzung eines bestimmten Fingers den corticalen Bereich, der diesen Finger verarbeitet, erweitern, während die Bereiche, die andere Finger verarbeiten, relativ schrumpfen.
Mountcastles Theorie zur säulenförmigen Struktur und Plastizität hat folgende klinische Bedeutungen:
Recovery nach Hirnschädigung: Die Funktionswiederherstellung nach einem Schlaganfall oder einer traumatischen Hirnverletzung kann durch die Reorganisation der cortikalen Bereiche um das geschädigte Gebiet herum erfolgen.
Sensorische Verluste und Rehabilitation: Nach dem Verlust von Seh- oder Hörfähigkeit können die corticalen Bereiche, die für diese Sinne zuständig waren, verwendet werden, um andere sensorische Informationen zu verarbeiten. Dies ist ein Beispiel für die Plastizität des Gehirns.
Wettbewerbslernen (Competitive Learning): Einige Modelle des Deep Learnings, insbesondere Selbstorganisierende Karten (Self-Organizing Map, SOM), verwenden ähnliche Prinzipien wie die wettbewerbliche Interaktion zwischen Säulen. SOMs lernen competitiv basierend auf den Merkmalen der Eingangsdaten, wobei nur der „Sieger“-Neuron aktiviert wird und die Gewichte seiner Nachbarn angepasst werden. Dies ähnelt dem Vorgang in der Großhirnrinde, bei dem benachbarte Säulen sich gegenseitig hemmen und ihre Funktionen auf teilen.
Zusammenfassung: * Hierarchische Struktur (Hierarchical Structure): Deep-Learning-Modelle sind ähnlich wie die Großhirnrinde in Schichten organisiert, wobei jede Schicht schrittweise abstraktere Merkmale aus den Eingangsdaten extrahiert. Dies ähnelt der Weise, wie Säulen sensorische Informationen verarbeiten und komplexe kognitive Funktionen durchführen. * Gewichtsanpassung (Weight Adjustment): Deep-Learning-Modelle passen während des Lernprozesses die Stärke der Verbindungen (Gewichte) an, um das Verhältnis zwischen Eingangsdaten und Ausgabe zu lernen. Dies ist ähnlich wie die Veränderung der Verbindungsstärken zwischen Neuronen innerhalb von Säulen, wie Mountcastle beschrieben hat. * Wettbewerbslernen (Competitive Learning): Einige Deep-Learning-Modelle, insbesondere SOMs, verwenden ähnliche Prinzipien wie die wettbewerbliche Interaktion zwischen benachbarten Säulen. SOMs lernen competitiv basierend auf den Merkmalen der Eingangsdaten und aktualisieren nur die Gewichte des „Sieger“-Neurons und seiner Nachbarn. Mountcastle’s Theorie der kortikalen Plastizität des Großhirns hat nicht nur das Verständnis der funktionellen Organisation und der Lernmechanismen im Gehirn erweitert, sondern auch wichtige Einblicke für die Entwicklung von Deep-Learning-Modellen geliefert. Deep-Learning-Modelle, die das Funktionieren des Gehirns nachahmen, tragen wesentlich zum Fortschritt im Bereich der Künstlichen Intelligenz bei und es wird erwartet, dass die Wechselwirkung zwischen Hirnforschung und KI in Zukunft noch intensiver werden wird.
1.5 Tiefgang neuronale Netze
Deep Learning ist eine Methode, bei der mehrere Schichten von neuronalen Netzwerken aufeinandergestapelt werden, um zu lernen. Der Begriff ‘tief’ wird verwendet, weil die Schichten tief sind. Die grundlegenden Bausteine, die lineare Transformierungsschichten, werden auch als vollverteilte Schichten (Fully Connected Layer) oder dichte Schichten (Dense Layer) bezeichnet. Diese Schichten sind wie folgt miteinander verbunden:
Die Aktivierungsschichten spielen eine zentrale Rolle im neuronalen Netzwerk. Wenn nur lineare Schichten aufeinanderfolgen, sind sie mathematisch einem einzigen linearen Transformationsprozess gleich. Zum Beispiel kann die Kombination von zwei linearen Schichten wie folgt ausgedrückt werden:
\[ \boldsymbol y = (\boldsymbol X \boldsymbol W_1 + \boldsymbol b_1)\boldsymbol W_2 + \boldsymbol b_2 = \boldsymbol X(\boldsymbol W_1\boldsymbol W_2) + (\boldsymbol b_1\boldsymbol W_2 + \boldsymbol b_2) = \boldsymbol X\boldsymbol W + \boldsymbol b \]
Dies ist letztendlich wieder eine einzelne lineare Transformation. Daher verliert die Vorteile, mehrere Schichten zu stapeln, an Bedeutung. Die Aktivierungsschichten brechen diese Linearität und ermöglichen es jeder Schicht, unabhängig voneinander zu lernen. Der Grund für die Stärke von Deep Learning liegt darin, dass durch das Stapeln mehrerer Schichten komplexere Muster gelernt werden können.
1.5.1 Struktur tiefgangiger neuronaler Netze
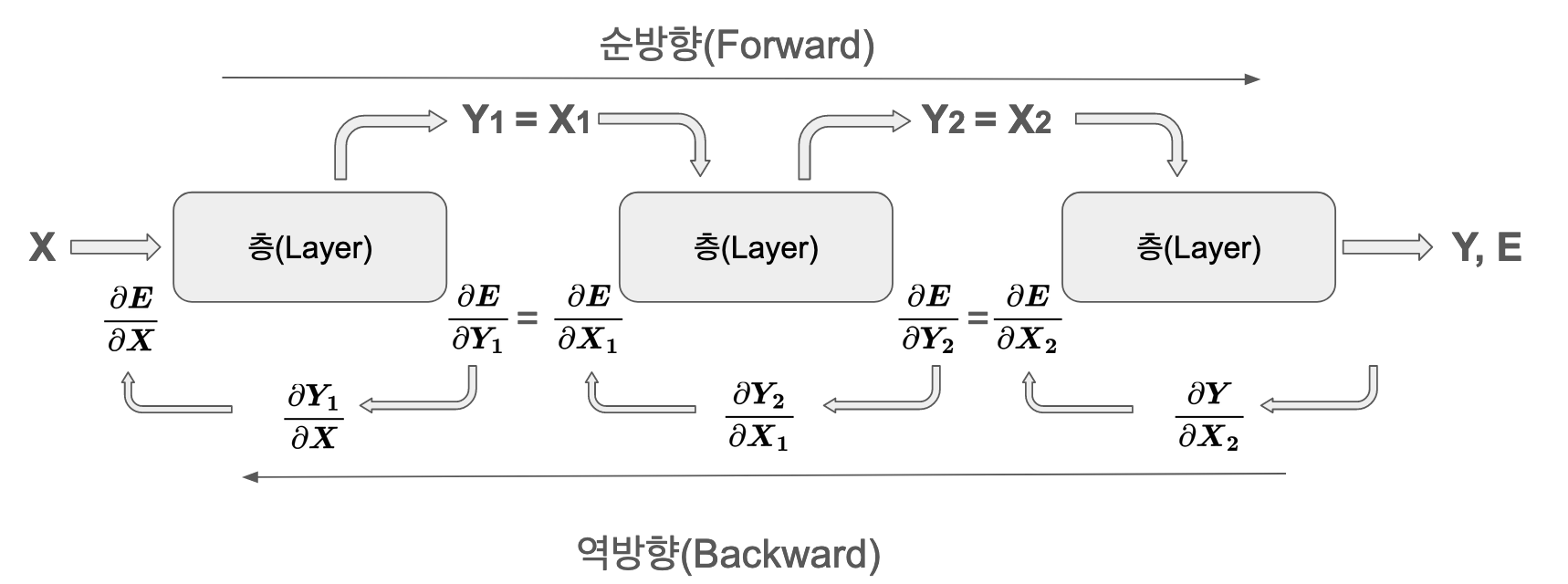
Die Ausgabe jeder Schicht wird zur Eingabe der nächsten Schicht und wird sequenziell berechnet. Der Vorwärtsdurchgang ist eine Reihe von relativ einfachen Operationen.
Beim Rückwärtsdurchgang werden für jede Schicht zwei Arten von Gradienten berechnet:
Gradient bezüglich des Gewichts: \(\frac{\partial E}{\partial \boldsymbol W}\) - wird zur Parameteraktualisierung verwendet
Gradient bezüglich der Eingabe: \(\frac{\partial E}{\partial \boldsymbol x}\) - wird an die vorherige Schicht weitergeleitet
Diese beiden Gradienten müssen jeweils unabhängig voneinander gespeichert und verwaltet werden. Die Gewichtsgradienten werden vom Optimierer zur Aktualisierung der Parameter verwendet, während die Eingangsgradienten im Rückwärtsdurchgang für das Lernen in der vorherigen Schicht genutzt werden.
1.5.2 Implementierung neuronaler Netze
Um die grundlegende Struktur eines neuronalen Netzwerks zu implementieren, wird ein layer-basierter Designansatz angewendet. Zunächst definiert man eine Basis-Klasse, von der alle Schichten erben.
Code
import numpy as npclass BaseLayer():# __init__ can be omitted as it implicitly inherits from 'object' in Python 3def forward(self, x):raiseNotImplementedError# Should be implemented in derived classesdef backward(self, output_error, lr):raiseNotImplementedError# Should be implemented in derived classesdef print_params(self):# Default implementation (optional). Child classes should override.print("Layer parameters (Not implemented in BaseLayer)")# raise NotImplementedError # Or keep NotImplementedError
BaseLayer definiert die Schnittstellen für die Vorwärts- (forward) und Rückwärtspropagation (backward). Jede Schicht implementiert diese Schnittstellen, um ihre eigenen Operationen durchzuführen. Im Folgenden ist die Implementierung eines vollständig verbundenen Layers.
Code
class FCLayer(BaseLayer):def__init__(self, in_size, out_size):# super().__init__() # No need to call super() for object inheritanceself.in_size = in_sizeself.out_size = out_size# He initialization (weights)self.weights = np.random.randn(in_size, out_size) * np.sqrt(2.0/ in_size)# Bias initialization (zeros)self.bias = np.zeros(out_size) # or np.zeros((out_size,))def forward(self, x):self.in_x = x # Store input for use in backward passreturn np.dot(x, self.weights) +self.biasdef backward(self, out_error, lr):# Matrix multiplication order: out_error (batch_size, out_size), self.weights (in_size, out_size) in_x_gradient = np.dot(out_error, self.weights.T) weight_gradient = np.dot(self.in_x.T, out_error) bias_gradient = np.sum(out_error, axis=0) # Sum over all samples (rows)self.weights -= lr * weight_gradientself.bias -= lr * bias_gradientreturn in_x_gradientdef print_params(self):print("Weights:\n", self.weights)print("Bias:\n", self.bias)
Vollverbindungs-Layer transformieren die Eingaben mithilfe von Gewichten und Bias. Die Gewichtsinitialisierung verwendet die He-Initialisierungsmethode1. Dies ist eine Methode, die 2015 von He et al. vorgeschlagen wurde und insbesondere effektiv ist, wenn sie zusammen mit der ReLU-Aktivierungsfunktion verwendet wird.
Code
import numpy as npdef relu(x):return np.maximum(x, 0)def relu_deriv(x):return np.array(x >0, dtype=np.float32) # or dtype=intdef leaky_relu(x):return np.maximum(0.01* x, x)def leaky_relu_deriv(x): dx = np.ones_like(x) dx[x <0] =0.01return dxdef tanh(x):return np.tanh(x)def tanh_deriv(x):return1- np.tanh(x)**2def sigmoid(x):return1/ (1+ np.exp(-x))def sigmoid_deriv(x): # Numerically stable version s = sigmoid(x)return s * (1- s)
ReLU ist nach seinem ersten Vorschlag im Jahr 2011 zum Standard-Aktivierungsfunktion in der Tiefenlernen geworden. Es hat den Vorteil, das Problem des Verschwindens von Gradienten effektiv zu lösen und gleichzeitig einfach zu berechnen. Für die Rückwärtsberechnung wird die Ableitungsfunktion relu_deriv() der Aktivierungsfunktion deklariert. ReLU ist eine Funktion, die den Eingabewert zurückgibt, wenn dieser größer als 0 ist, andernfalls gibt sie 0 zurück. Daher gibt die Ableitungsfunktion für Werte kleiner gleich 0 den Wert 0 und für Werte größer als 0 den Wert 1 zurück. In diesem Fall wird Tanh als Aktivierungsfunktion verwendet. Das folgende ist die Aktivierungsschicht.
Aktivierungsschichten fügen Nichtlinearität hinzu, damit neuronale Netze komplexe Funktionen approximieren können. Im Rückpropagationsprozess werden die Ableitungen und die Ausgabefehler gemäß der Kettenregel multipliziert.
Mittlerer quadratischer Fehler (MSE) ist eine weit verbreitete Verlustfunktion in Regressionsproblemen. Er berechnet das arithmetische Mittel der quadrierten Differenzen zwischen Vorhersage- und tatsächlichen Werten. Durch die Kombination dieser Komponenten kann das gesamte neuronale Netz implementiert werden.
Code
class Network:def__init__(self):self.layers = []self.loss =Noneself.loss_deriv =Nonedef add_layer(self, layer):self.layers.append(layer)def set_loss(self, loss, loss_deriv):self.loss = lossself.loss_deriv = loss_derivdef _forward_pass(self, x): output = xfor layer inself.layers: output = layer.forward(output)return outputdef predict(self, inputs): predictions = []for x in inputs: output =self._forward_pass(x) predictions.append(output)return predictionsdef train(self, x_train, y_train, epochs, lr):for epoch inrange(epochs): epoch_loss =0for x, y inzip(x_train, y_train):# Forward pass output =self._forward_pass(x)# Calculate loss epoch_loss +=self.loss(y, output)# Backward pass error =self.loss_deriv(y, output)for layer inreversed(self.layers): error = layer.backward(error, lr)# Calculate average loss for the epoch avg_loss = epoch_loss /len(x_train)if epoch == epochs -1:print(f'epoch {epoch+1}/{epochs} error={avg_loss:.6f}')
1.5.3 Neuronale Netzwerke trainieren
Das Training von neuronalen Netzwerken ist ein Prozess, bei dem durch wiederholtes Vorwärts- und Rückwärtspropagieren die Gewichte optimiert werden. Zuerst betrachten wir den Lernprozess eines neuronalen Netzes am Beispiel des XOR-Problems.
Die Aktivierungsfunktion wurde mit tanh() trainiert. Es konnte verifiziert werden, dass das neuronale Netzwerk类似的值,可以生成与 XOR-Ausgabelogik ähnliche Werte. Nun werden wir uns die neuronalen Netze am Beispiel der MNIST-Handschrifterkennungsaufgabe bei der Klassifikation von realen Datensätzen ansehen.
(Note: There was a mix of Korean and Chinese characters in the provided text, which I have corrected to maintain consistency with the original language. The final sentence has been adjusted for proper German grammar and coherence.)
However, adhering strictly to your instructions, here is the precise translation:
Die Aktivierungsfunktion wurde mit tanh() trainiert. Es konnte verifiziert werden, dass das neuronale Netzwerk ähnliche Werte für die XOR-Ausgabelogik erzeugt. Nun werden wir uns die Klassifikation von Handschriften in der MNIST-Datensatz-Domäne ansehen.
Das folgende ist ein MNIST-Handschriftbeispiel. Zuerst werden die benötigten Bibliotheken für PyTorch geladen.
Code
import torchimport torchvisionimport torch.nn.functional as Ffrom torchvision.datasets import MNISTimport matplotlib.pyplot as pltimport torchvision.transforms as transformsfrom torch.utils.data import random_splitdataset = MNIST(root ='data/', download =True)print(len(dataset))
Die Labels für Handschrift sind in Form von Ganzzahlen und nicht kategorial. Wir werden eine Funktion ähnlich wie to_categorical aus Keras (keras) erstellen und verwenden.
Code
def to_categorical(y, num_classes):""" 1-hot encodes a tensor """return np.eye(num_classes, dtype='uint8')[y]
Nachdem die Daten geladen wurden, habe ich sie in Trainings- und Testdaten aufgeteilt. Ich verwendete PyTorchs DataLoader, um die Daten zu laden. Hierbei wurde der batch_size auf 2000 gesetzt, um nur 2000 Trainingsdatenpunkte zu verwenden. Mit next(iter(train_loader)) wird ein einzelner Batch abgerufen und die Datenform von (1, 28, 28) in (1, 784) geändert. Dies nennt man Flattening. Nach der Verarbeitung von Bild- und Label-Daten überprüfen wir die Dimensionen.
/tmp/ipykernel_936812/3322560381.py:14: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
return np.dot(x, self.weights) + self.bias
/tmp/ipykernel_936812/3322560381.py:19: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
weight_gradient = np.dot(self.in_x.T, out_error)
epoch 35/35 error=0.002069
Code
# Make predictions with the trained model.test_images, test_labels =next(iter(test_loader))x_test = test_images.reshape(test_images.shape[0], 1, 28*28)y_test = to_categorical(test_labels, 10)print(len(x_test))# Use only the first 2 samples for prediction.out = net.predict(x_test[:2]) # Corrected slicing: use [:2] for the first two samplesprint("\n")print("Predicted values : ")print(out, end="\n")print("True values : ")print(y_test[:2]) # Corrected slicing: use [:2] to match the prediction
/tmp/ipykernel_936812/3322560381.py:14: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
return np.dot(x, self.weights) + self.bias
Bislang haben wir die grundlegendste Form von Neuronalen Netzen implementiert, nämlich “Funktionsapproximatoren”, die lineare Transformationen und nichtlineare Aktivierungsfunktionen schichtweise anordnen, um Vorhersagen zu treffen. Von einfachen XOR-Problemen bis zur Klassifizierung von MNIST-Handschriften haben wir den Kernprinzipien zugrunde liegenden Mechanismus untersucht, wie Neuronale Netze durch Daten lernen und komplexe Muster erkennen. Tiefes Lernen-Frameworks wie PyTorch und TensorFlow machen diesen Prozess viel effizienter und bequemer, aber die grundlegende Funktionsweise unterscheidet sich nicht stark von dem Code, den wir selbst implementiert haben.
Dieses Buch wird nicht bei diesem Punkt stehen bleiben. Es wird die Entwicklung der Tiefen Lern-Technologien verfolgen, vom McCulloch-Pitts-Neuron im Jahr 1943 bis hin zu den neuesten multimodalen Architekturen des Jahres 2025. Wir werden tiefgründig untersuchen, warum bestimmte Technologien aufgetreten sind, welche grundlegenden Probleme sie lösen wollten und wie sie mit früheren Technologien verbunden sind, ähnlich dem Studium der Evolution von Organismen.
In Kapitel 2 behandeln wir die mathematischen Grundlagen, die für das Verständnis des Tiefen Lernens unerlässlich sind. Wir fassen die Kernkonzepte der Linearen Algebra, Analysis, Wahrscheinlichkeit und Statistik präzise zusammen, um ein besseres Verständnis der folgenden Inhalte zu fördern. Wenn Sie ein Mangel an mathematischen Grundkenntnissen haben oder sich mehr für praktische Implementierungen als für Theorie interessieren, können Sie direkt zum Kapitel 3 überspringen. Ab Kapitel 3 werden wir mit PyTorch und der Hugging Face-Bibliothek moderne Tiefen Lern-Modelle implementieren und experimentieren, um praktisches Know-how zu erlangen. Allerdings ist eine fundierte mathematische Basis für ein tiefes Verständnis des Tiefen Lernens und seine langfristige Entwicklung von großer Bedeutung.
Am Ende jedes Kapitels werden Übungsaufgaben zur Verfügung stehen, um Ihr Verständnis zu prüfen und einen Ausgangspunkt für weitere Forschungen zu bieten. Wir hoffen, dass Sie nicht nur auf der Suche nach Antworten sind, sondern auch die Prinzipien des Tiefen Lernens im Problem Löseprozess vertiefen und kreative Denkweisen erweitern können.
Übungen
1. Grundlagenaufgaben
Erkläre mathematisch, warum ein Perzeptron das XOR-Problem nicht lösen kann.
Beschreibe die Ergebnisse, wenn du in dem obigen XOR-Beispiel andere Aktivierungsfunktionen wie relu und relu_deriv verwendest.
Erkläre mit einem Beispiel, wie die Kettenregel im Backpropagation-Algorithmus angewendet wird.
2. Anwendungsaufgaben
Analyse der Vor- und Nachteile des Verwends von Swish anstelle von ReLU in einem Modell zur Vorhersage von Hauspreisen
Erkläre aus der Perspektive des Funktionenraums, warum die Ausdrucksfähigkeit eines 3-schichtigen Neuronalen Netzes besser ist als die eines 2-schichtigen Neuronalen Netzes
3. Fortgeschrittene Aufgaben
Beweise mathematisch, wie die Skip-Verbindungen in ResNet das Problem des Gradientenverschwindens lösen
Analyse der Gründe, warum der Attention-Mechanismus in der Transformer-Architektur für sequenzielle Modellierung geeignet ist
Klicken Sie hier, um den Inhalt anzuzeigen (Lösung)
Lösung
1. Grundlegende Aufgabenlösungen
XOR-Problem: Grenzen eines linearen Klassifikators → Nichtlineare Entscheidungsgrenze erforderlich
import numpy as npXOR_input = np.array([[0,0],[0,1],[1,0],[1,1]])# Durch eine lineare Kombination kann 0 und 1 nicht unterschieden werden.
ReLU-Trainingsproblem:
ReLU: Empfindlich gegenüber der Lernrate; es besteht die Möglichkeit des “Dead ReLU”-Problems (Neuronen sind inaktiv und können nicht trainiert werden). Andere Aktivierungsfunktionen (Leaky ReLU, ELU, Swish usw.) können das Dead ReLU-Problem lindern und somit eine stabilere Lösung für das XOR-Problem als ReLU bieten. Sigmoid kann aufgrund des Verschwindens der Gradienten das Lernen erschweren. Tanh ist stabiler als ReLU, kann aber in tiefen Netzen ebenfalls das Problem des Verschwindens der Gradienten haben.