Code
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“Der Unterschied zwischen Theorie und Praxis ist größer als der Unterschied zwischen Theorie und Praxis.” - Yann LeCun, Turing-Preisträger 2018
Der Erfolg von Deep-Learning-Modellen hängt stark von effektiven Optimierungsalgorithmen und geeigneten Strategien zur Gewichtsinitialisierung ab. In diesem Kapitel untersuchen wir eingehend die Kernaspekte der Optimierung und Initialisierung beim Training von Deep-Learning-Modellen und stellen Methoden vor, um diesen Prozess durch Visualisierung intuitiv zu verstehen. Zunächst betrachten wir die Entwicklung verschiedener Gewichtsinitialisierungsverfahren, die die Grundlage des Neuronalen Netzes bilden, sowie ihre mathematischen Prinzipien. Anschließend vergleichen und analysieren wir die Funktionsweise und Leistung von modernen Optimierungsalgorithmen wie Gradient Descent, Adam, Lion, Sophia und AdaFactor. Insbesondere untersuchen wir nicht nur den theoretischen Hintergrund, sondern auch, wie jeder Algorithmus in der Praxis während des Trainings von Deep-Learning-Modellen funktioniert. Schließlich stellen wir verschiedene Techniken vor, um hochdimensionale Verlustfunktionenräume (loss landscapes) zu visualisieren und zu analysieren, und bieten damit tiefgründige Einblicke in die Lern-Dynamik (learning dynamics) von Deep-Learning-Modellen.
Die Initialisierung der Parameter in neuronalen Netzen ist einer der entscheidenden Faktoren, die die Konvergenz, das Lerneffizienz und die endgültige Leistung eines Modells bestimmen. Eine fehlerhafte Initialisierung kann ein wesentlicher Grund für das Scheitern des Trainings sein. PyTorch bietet verschiedene Initialisierungsmethoden über das torch.nn.init-Modul an, die Details sind in der offiziellen Dokumentation (https://pytorch.org/docs/stable/nn.init.html) zu finden. Die Entwicklung von Initialisierungsmethoden spiegelt die Geschichte wider, wie Deep-Learning-Forscher die Herausforderungen beim Training neuronaler Netze überwunden haben. Insbesondere wurden unangemessene Initialisierungen als Hauptursache für Gradientenverschwinden (vanishing gradient) und -explosion (exploding gradient), die das Lernen in tiefen neuronalen Netzen behindern, identifiziert. Mit der Einführung von großen Sprachmodellen wie GPT-3 und LaMDA wurde die Bedeutung der Initialisierung noch stärker hervorgehoben. Je größer das Modell, desto größer ist der Einfluss der Anfangsparameter auf die frühen Phasen des Lernens. Daher ist es ein wesentlicher Schritt bei der Entwicklung von Deep-Learning-Modellen, eine geeignete Initialisierungsstrategie basierend auf den Eigenschaften und dem Umfang des Modells auszuwählen.
Die Entwicklung der Initialisierungsmethoden für neuronale Netze ist das Ergebnis tiefgreifender mathematischer Theorien und zahlreicher experimenteller Verifizierungen. Jede Methode wurde entweder entwickelt, um bestimmte Problemstellungen (z.B. die Verwendung spezifischer Aktivierungsfunktionen, die Tiefe des Netzwerks, den Modelltyp) zu lösen oder um die Lern-Dynamik (learning dynamics) zu verbessern, und hat sich weiterentwickelt, um neuen Herausforderungen entgegenzuwirken.
Die folgenden Initialisierungsmethoden werden in diesem Buch im Vergleich analysiert. (Der vollständige Implementierungscode befindet sich in der Datei chapter_04/initialization/base.py.)
!pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2import torch
import torch.nn as nn
import numpy as np
# Set seed
np.random.seed(7)
torch.manual_seed(7)
from dldna.chapter_05.initialization.base import init_methods, init_weights_lecun, init_weights_scaled_orthogonal, init_weights_lmomentum # init_weights_emergence, init_weights_dynamic 삭제
init_methods = {
# Historical/Educational Significance
'lecun': init_weights_lecun, # The first systematic initialization proposed in 1998
'xavier_normal': nn.init.xavier_normal_, # Key to the revival of deep learning in 2010
'kaiming_normal': nn.init.kaiming_normal_, # Standard for the ReLU era, 2015
# Modern Standard
'orthogonal': nn.init.orthogonal_, # Important in RNN/LSTM
'scaled_orthogonal': init_weights_scaled_orthogonal, # Optimization of deep neural networks
# 2024 Latest Research
'l-momentum': init_weights_lmomentum # L-Momentum Initialization
}LeCun-Initialisierung (1998): \(std = \sqrt{\frac{1}{n_{in}}}\)
Xavier-Initialisierung (Glorot, 2010): \(std = \sqrt{\frac{2}{n_{in} + n_{out}}}\)
Kaiming-Initialisierung (He, 2015): \(std = \sqrt{\frac{2}{n_{in}}}\)
Die L-Momentum-Initialisierung ist eine neuere Methode, die im Jahr 2024 vorgeschlagen wurde und von traditionellen momentum-basierten Optimierungsverfahren inspiriert ist. Sie kontrolliert den L-Momentum der initialen Gewichtsmatrix.
Formel:
\(W \sim U(-\sqrt{\frac{6}{n_{in}}}, \sqrt{\frac{6}{n_{in}}})\) \(W = W \cdot \sqrt{\frac{\alpha}{Var(W)}}\)
Hierbei ist \(U\) die Gleichverteilung, \(\alpha\) ein Wert, der den L-Momentum darstellt und das Quadrat des Momentum-Werts aus dem Optimierer verwendet.
Das Ziel besteht darin, in den ersten Phasen die Gradientenschwankungen zu reduzieren, um eine stabile Lernphase zu ermöglichen.
Spektrale Kontrolle (Spectral Control): Die Verteilung der Singulärwerte der Gewichtsmatrix muss kontrolliert werden, um numerische Stabilität während des Lernprozesses sicherzustellen.
\(\sigma_{max}(W) / \sigma_{min}(W) \leq C\)
Dies ist besonders wichtig in Strukturen wie Rekurrenten Neuronalen Netzen (RNN), bei denen Gewichtsmatrizen wiederholt multipliziert werden.
Expressivitätsoptimierung (Expressivity Optimization): Die effektive Rangfolge (effective rank) der Gewichtsmatrix sollte maximiert werden, um sicherzustellen, dass das Netzwerk ausreichende Expressivität besitzt.
\(rank_{eff}(W) = \frac{\sum_i \sigma_i}{\max_i \sigma_i}\) Neueste Forschungen bemühen sich darum, diese Prinzipien explizit zu erfüllen.
Zusammenfassend lässt sich sagen, dass die Initialisierungsmethoden sorgfältig unter Berücksichtigung der Wechselwirkung mit der Modellgröße, -struktur, Aktivierungsfunktionen und Optimierungsalgorithmen ausgewählt werden müssen. Dies ist darauf zurückzuführen, dass sie erheblichen Einfluss auf die Lerngeschwindigkeit, Stabilität und letztlich die Endleistung des Modells haben.
Mit zunehmender Tiefe des Neuronalen Netzes ist es von größter Wichtigkeit, die statistischen Eigenschaften (insbesondere die Varianz) der Signale während des Vorwärts- und Rückwärtspropagationsprozesses zu erhalten. Dies verhindert, dass Signale verschwinden (vanishing) oder explodieren (exploding), und ermöglicht so eine stabile Lernphase.
Sei \(h_l\) die Aktivierungswerte des \(l\)-ten Layers, \(W_l\) die Gewichtsmatrix, \(b_l\) der Bias, und \(f\) die Aktivierungsfunktion. Dann kann die Vorwärtspropagation wie folgt ausgedrückt werden:
\(h_l = f(W_l h_{l-1} + b_l)\)
Angenommen, die Elemente des Eingangssignals \(h_{l-1} \in \mathbb{R}^{n_{in}}\) sind unabhängige Zufallsvariablen mit Mittelwert 0 und Varianz \(\sigma^2_{h_{l-1}}\), und die Elemente der Gewichtsmatrix \(W_l \in \mathbb{R}^{n_{out} \times n_{in}}\) sind unabhängige Zufallsvariablen mit Mittelwert 0 und Varianz \(Var(W_l)\), und der Bias ist \(b_l = 0\). Unter der Annahme, dass die Aktivierungsfunktion linear ist, gilt:
\(Var(h_l) = n_{in} Var(W_l) Var(h_{l-1})\) (wobei \(n_{in}\) die Eingangsdimension des \(l\)-ten Layers ist)
Um die Varianz der Aktivierungswerte zu erhalten, muss \(Var(h_l) = Var(h_{l-1})\) gelten. Daher muss \(Var(W_l) = 1/n_{in}\) sein.
Während des Rückpropagationprozesses gilt für den Fehlergradienten \(\delta_l = \frac{\partial L}{\partial h_l}\) (wobei \(L\) die Verlustfunktion ist), der folgende Zusammenhang:
\(\delta_{l-1} = W_l^T \delta_l\) (unter der Annahme, dass die Aktivierungsfunktion linear ist)
Folglich muss für die Varianzerhaltung während des Rückpropagationprozesses \(Var(\delta_{l-1}) = n_{out}Var(W_l)Var(\delta_l)\) gelten. Daher muss \(Var(W_l) = 1/n_{out}\) sein. (wobei \(n_{out}\) die Ausgangsdimension des \(l\)-ten Layers ist)
ReLU-Aktivierungsfunktion
Die ReLU-Funktion (\(f(x) = max(0, x)\)) macht die Hälfte der Eingaben zu Null und neigt daher dazu, die Varianz der Aktivierungswerte zu reduzieren. Kaiming He schlug zur Korrektur folgende Varianzerhaltungsgleichung vor:
\(Var(W_l) = \frac{2}{n_{in}} \quad (\text{ReLU-spezifisch})\)
Dies kompensiert die Varianzreduktion, die durch das Durchlaufen der ReLU-Funktion entsteht, indem sie verdoppelt wird.
Leaky-ReLU-Aktivierungsfunktion
Im Fall des Leaky ReLU (\(f(x) = max(\alpha x, x)\), wobei \(\alpha\) eine kleine Konstante ist), lautet die Gleichung:
\(Var(W_l) = \frac{2}{(1 + \alpha^2) n_{in}}\)
Eine Methode zur Initialisierung nutzt das Inverse der Fisher Information Matrix (FIM). Die FIM enthält Krümmungsinformationen im Parameterraum, was zu einer effizienteren Initialisierung führen kann. (Für weitere Details siehe Referenz [4] Martens, 2020).
Das Singulärwertzerlegung (Singular Value Decomposition, SVD) der Gewichtsmatrix \(W \in \mathbb{R}^{m \times n}\) wird durch \(W = U\Sigma V^T\) dargestellt. Hierbei ist \(\Sigma\) eine Diagonalmatrix und die diagonalen Elemente sind die Singulärwerte von \(W\) (\(\sigma_1 \geq \sigma_2 \geq ... \geq 0\)). Wenn der maximale Singulärwert (\(\sigma_{max}\)) der Gewichtsmatrix zu groß ist, kann dies zu explodierenden Gradienten (exploding gradient) führen; wenn der minimale Singulärwert (\(\sigma_{min}\)) zu klein ist, kann dies zu verschwindenden Gradienten (vanishing gradient) führen.
Daher ist es wichtig, das Verhältnis der Singulärwerte (Konditionszahl, condition number) \(\kappa = \sigma_{max}/\sigma_{min}\) zu kontrollieren. Je näher \(\kappa\) an 1 liegt, desto stabiler ist die Gradientenfluss.
Theorem 2.1 (Saxe et al., 2014): Bei einer orthogonal initialisierten tiefen linearen neuronalen Netzwerks, wenn die Gewichtsmatrix \(W_l\) jedes Layers eine orthogonale Matrix ist, bleibt die Frobenius-Norm der Jacobimatrix \(J\) des Outputs bezüglich der Eingabe bei 1.
\(||J||_F = 1\)
Dies hilft, das Problem von verschwindenden oder explodierenden Gradienten auch in sehr tiefen Netzwerken zu lindern.
Miyato et al. (2018) schlugen die Spektralnormalisierung (Spectral Normalization) vor, um die Stabilität des GAN-Lernprozesses zu erhöhen, indem sie den Spektralnorm der Gewichtsmatrix (maximaler Singulärwert) einschränken.
\(W_{SN} = \frac{W}{\sigma_{max}(W)}\)
Diese Methode ist insbesondere effektiv im GAN-Lernen und wird in letzter Zeit auch auf andere Modelle wie Vision Transformers angewendet.
Die Fähigkeit einer Gewichtsmatrix \(W\), verschiedene Merkmale zu repräsentieren, kann durch die Gleichförmigkeit der Verteilung der Singulärwerte gemessen werden. Der effektive Rang (effective rank) wird wie folgt definiert.
\(\text{rank}_{eff}(W) = \exp\left( -\sum_{i=1}^r p_i \ln p_i \right) \quad \text{where } p_i = \frac{\sigma_i}{\sum_j \sigma_j}\)
Dabei ist \(r\) der Rang von \(W\), \(\sigma_i\) der i-te Singulärwert, und \(p_i\) der normierte Singulärwert. Der effektive Rang ist ein Maß für die Verteilung der Singulärwerte; je höher der Wert, desto gleichmäßiger sind die Singulärwerte verteilt, was wiederum eine höhere Ausdrucksfähigkeit anzeigt.
| Methode | Beschreibung |
|---|---|
| Xavier-Initialisierung | Initialisiert Gewichte unter Annahme einer Gleichverteilung oder einer Normalverteilung, um die Varianz der Aktivierungen und Gradienten zu stabilisieren. |
| He-Initialisierung | Ähnlich wie Xavier-Initialisierung, aber optimiert für ReLU-Aktivierungsfunktionen. |
| Orthogonale Initialisierung | Initialisiert Gewichte als orthogonale Matrizen, um die Gradientenfluss zu stabilisieren. |
| Spectral Normalization | Skaliert Gewichte durch ihre Spektralnorm, um die Stabilität des Lernprozesses in GANs zu verbessern. |
| Initialisierungsmethode | Singulärwertverteilung |
| ———————– | ————————————————————————————- |
| Xavier | Relativ schnell abnehmend |
| Kaiming | An ReLU-Aktivierungsfunktion angepasst (relativ weniger Abnahme) |
| Orthogonal | Alle Singulärwerte sind 1 |
| Emergence-Promoting | Nach Netzwerkgröße angepasst, relativ langsam abnehmend (ähnlich heavy-tailed distribution) |
Die Emergence-Promoting-Initialisierung ist eine neuere Technik, die zur Förderung emergenter Fähigkeiten in großen Sprachmodellen (LLM) vorgeschlagen wurde. Diese Methode passt die Varianz der initialen Gewichte an die Größe des Netzwerks (insbesondere die Tiefe der Schichten) an und hat die Wirkung, den effektiven Rang zu erhöhen.
Chen et al. (2023) schlagen für Transformer-Modelle folgenden Skalierungsfaktor \(\nu_l\) vor:
\(\nu_l = \frac{1}{\sqrt{d_{in}}} \left( 1 + \frac{\ln l}{\ln d} \right)\)
Dabei ist \(d_{in}\) die Eingabedimension, \(l\) der Index der Schicht und \(d\) die Tiefe des Modells. Diesen Skalierungsfaktor multipliziert man mit der Standardabweichung der Gewichtsmatrix zur Initialisierung. Das heißt, man sampelt aus einer Normalverteilung mit der Standardabweichung \(\nu_l \cdot \sqrt{2/n_{in}}\).
Die Neural Tangent Kernel (NTK)-Theorie, wie von Jacot et al.(2018) entwickelt, ist ein nützliches Werkzeug zur Analyse der Lerndynamik “sehr breiter” (unendlich breiter) neuronalen Netze. Nach der NTK-Theorie ist die Erwartungswertmatrix des Hesse-Matrix bei Initialisierung proportional zur Identitätsmatrix. Das heißt,
\(\lim_{n_{in} \to \infty} \mathbb{E}[\nabla^2 \mathcal{L}] \propto I\) (bei Initialisierung)
Dies deutet darauf hin, dass die Xavier-Initialisierung für breite neuronale Netze eine nahezu optimale Initialisierung bereitstellt.
Kürzliche Studien wie MetaInit (2023) schlagen Methoden vor, um durch Metalernen die optimale Initialisierungsverteilung für eine gegebene Architektur und Datensatz zu lernen.
\(\theta_{init} = \arg\min_\theta \mathbb{E}_{\mathcal{T}}[\mathcal{L}(\phi_{fine-tune}(\theta, \mathcal{T}))]\)
Dabei ist \(\theta\) der Initialisierungsparameter, \(\mathcal{T}\) die Lernaufgabe und \(\phi\) den Prozess des Fine-Tunings eines mit \(\theta\) initialisierten Modells darstellt.
In letzter Zeit werden auch Initialisierungsmethoden erforscht, die von den Prinzipien der Physik inspiriert sind. Zum Beispiel wurden Methoden vorgeschlagen, die auf der Schrödinger-Gleichung der Quantenmechanik oder den Navier-Stokes-Gleichungen der Strömungsmechanik basieren, um den Informationsfluss zwischen den Schichten zu optimieren. Allerdings befinden sich diese Ansätze noch in einem frühen Forschungsstadium und ihre Praktikabilität wurde bisher nicht überprüft.
Um zu verstehen, welche Auswirkungen die verschiedenen betrachteten Initialisierungsverfahren tatsächlich auf das Modelltraining haben, werden wir einfache Modelle verwenden, um Vergleichsexperimente durchzuführen. Wir trainieren die Modelle mit den jeweiligen Initialisierungsmethoden unter gleichen Bedingungen und analysieren die Ergebnisse. Die Bewertungskriterien sind wie folgt.
| Bewertungskriterium | Bedeutung | Gewünschte Eigenschaft |
|---|---|---|
| Fehlerrate (%) | Endgültige Vorhersageleistung des Modells (niedriger ist besser) | Niedriger ist besser |
| Konvergenzgeschwindigkeit | Neigung der Lernkurve (Stabilität des Lernprozesses) | Niedriger (steeper is faster convergence) |
| Durchschnittlicher Konditionszahl | Numerische Stabilität der Gewichtsmatrix | Niedriger (näher an 1 ist besser) |
| Spektralnorm | Größe der Gewichtsmatrix (maximale Singulärwerte) | Angemessener Wert, weder zu groß noch zu klein |
| Effektiver Rangverhältnis | Ausdrucksfähigkeit der Gewichtsmatrix (Uniformität der Singulärwertverteilung) | Höher ist besser |
| Laufzeit(s) | Trainingsdauer | Niedriger ist besser |
from dldna.chapter_04.models.base import SimpleNetwork
from dldna.chapter_04.utils.data import get_data_loaders, get_device
from dldna.chapter_05.initialization.base import init_methods
from dldna.chapter_05.initialization.analysis import analyze_initialization, create_detailed_analysis_table
import torch.nn as nn
device = get_device()
# Initialize data loaders
train_dataloader, test_dataloader = get_data_loaders()
# Detailed analysis of initialization methods
results = analyze_initialization(
model_class=lambda: SimpleNetwork(act_func=nn.PReLU()),
init_methods=init_methods,
train_loader=train_dataloader,
test_loader=test_dataloader,
epochs=3,
device=device
)
# Print detailed analysis results table
create_detailed_analysis_table(results)
Initialization method: lecun/home/sean/Developments/expert_ai/books/dld/dld/chapter_04/experiments/model_training.py:320: UserWarning: std(): degrees of freedom is <= 0. Correction should be strictly less than the reduction factor (input numel divided by output numel). (Triggered internally at ../aten/src/ATen/native/ReduceOps.cpp:1823.)
'std': param.data.std().item(),
Initialization method: xavier_normal
Initialization method: kaiming_normal
Initialization method: orthogonal
Initialization method: scaled_orthogonal
Initialization method: l-momentumInitialization Method | Error Rate (%) | Convergence Speed | Average Condition Number | Spectral Norm | Effective Rank Ratio | Execution Time (s)
---------------------|--------------|-----------------|------------------------|-------------|--------------------|------------------
lecun | 0.48 | 0.33 | 5.86 | 1.42 | 0.89 | 30.5
xavier_normal | 0.49 | 0.33 | 5.53 | 1.62 | 0.89 | 30.2
kaiming_normal | 0.45 | 0.33 | 5.85 | 1.96 | 0.89 | 30.1
orthogonal | 0.49 | 0.33 | 1.00 | 0.88 | 0.95 | 30.0
scaled_orthogonal | 2.30 | 1.00 | 1.00 | 0.13 | 0.95 | 30.0
l-momentum | nan | 0.00 | 5.48 | 19.02 | 0.89 | 30.1Das Experiment wurde in der folgenden Tabelle zusammengefasst.
| Initialisierungsmethode | Fehlerquote (%) | Konvergenzgeschwindigkeit | Durchschnittliche Bedingungszahl | Spektralnorm | Effektiver Rang-Verhältnis | Ausführungszeit (s) |
|---|---|---|---|---|---|---|
| lecun | 0.48 | 0.33 | 5.66 | 1.39 | 0.89 | 23.3 |
| xavier_normal | 0.48 | 0.33 | 5.60 | 1.64 | 0.89 | 23.2 |
| kaiming_normal | 0.45 | 0.33 | 5.52 | 1.98 | 0.89 | 23.2 |
| orthogonal | 0.49 | 0.33 | 1.00 | 0.88 | 0.95 | 23.3 |
| scaled_orthogonal | 2.30 | 1.00 | 1.00 | 0.13 | 0.95 | 23.3 |
| l-momentum | nan | 0.00 | 5.78 | 20.30 | 0.89 | 23.2 |
Die folgenden Punkte sind in den Experimentsergebnissen bemerkenswert:
Kaiming Initialisierung zeigt eine ausgezeichnete Leistung: Kaiming Initialisierung zeigte die niedrigste Fehlerquote von 0.45%. Dies ist ein Ergebnis, das die optimale Kombination mit der ReLU-Aktivierungsfunktion zeigt und bestätigt, dass Kaiming Initialisierung effektiv bei Verwendung mit ReLU-ähnlichen Funktionen ist.
Stabilität von orthogonalen Methoden: Orthogonale Initialisierung zeigte die beste numerische Stabilität mit einer Bedingungszahl von 1.00. Dies bedeutet, dass Gradienten während des Lernprozesses nicht verzerrt und gut weitergegeben werden, was insbesondere für Modelle wie rekurrente Neuronale Netze (RNNs), bei denen Gewichtsmatrizen wiederholt multipliziert werden, wichtig ist. Allerdings zeigte die Fehlerquote in diesem Experiment relativ hoch, was auf die Eigenschaften des verwendeten Modells (einfaches MLP) zurückzuführen sein könnte.
Probleme mit der skalierten orthogonalen Initialisierung: Die skalierte orthogonale Initialisierung zeigte eine sehr hohe Fehlerquote von 2.30%. Dies deutet darauf hin, dass diese Initialisierungsmethode für das gegebene Modell und Datensatz nicht geeignet ist oder zusätzliche Hyperparameteranpassung erforderlich ist. Es könnte sein, dass der Skalierungsfaktor (scaling factor) zu klein war, sodass das Lernen nicht ordnungsgemäß stattfand.
Instabilität der L-Momentum-Initialisierung: L-Momentum hat eine Fehlerrate und Konvergenzgeschwindigkeit von nan und 0.00, was darauf hinweist, dass das Lernen komplett fehlgeschlagen ist. Der spektrale Norm von 20.30 ist sehr hoch, was darauf hindeutet, dass die Anfangswerte der Gewichte zu groß waren und eine Divergenz verursacht haben könnten.
Die Initialisierung von Deep-Learning-Modellen ist ein Hyperparameter, der sorgfältig ausgewählt werden sollte, indem man die Architektur des Modells, die Aktivierungsfunktionen, die Optimierungsalgorithmen und die Eigenschaften des Datensatzes berücksichtigt. Folgende Punkte sollten bei der Auswahl von Initialisierungsmethoden in der Praxis berücksichtigt werden.
Initialisierung ist wie der “versteckte Held” des Deep-Learning-Modelltrainings. Eine korrekte Initialisierung kann entscheidend für den Erfolg oder Misserfolg des Modelltrainings sein und spielt eine entscheidende Rolle bei der Maximierung der Leistung und der Verringerung der Trainingszeit. Auf Basis der in diesem Abschnitt vorgestellten Richtlinien und der neuesten Forschungstrends wünsche ich Ihnen, die für Ihr Deep-Learning-Modell am besten geeignete Initialisierungsstrategie zu finden.
Herausforderung: Wie kann man das Problem lösen, dass Gradient Descent in lokale Minima gerät oder die Lernrate zu langsam ist?
Forschers Qualen: Eine einfache Reduzierung der Lernrate war nicht ausreichend. In einigen Fällen wurde das Training zu langsam und dauerte sehr lange, in anderen Fällen divergierte es und schlug fehl. Wie bei einem Nebelverhangenen Bergpfad, auf dem man sich tastend hinunterarbeitet, war der Weg zum Optimum beschwerlich. Obwohl verschiedene Optimierungsalgorithmen wie Momentum, RMSProp, Adam entstanden sind, gab es immer noch kein allumfassendes Lösungsmittel für alle Probleme.
Die strahlende Entwicklung des Deep Learnings ist nicht nur durch die Innovation von Modellstrukturen, sondern auch durch die Entwicklung effizienter Optimierungsalgorithmen getrieben worden. Optimierungsalgorithmen sind wie der Kernmotor, der den Prozess der automatisierten und beschleunigten Suche nach dem Minimum der Verlustfunktion (loss function) steuert. Die Effizienz und Stabilität dieses Motors bestimmt die Lernrate und das Endresultat des Deep-Learning-Modells.
Optimierungsalgorithmen haben sich über Jahrzehnte hinweg, wie lebende Organismen, durch die Lösung von drei Kernproblemen weiterentwickelt.
Jede dieser Herausforderungen führte zur Erschaffung neuer Algorithmen, und die Suche nach besseren Algorithmen geht weiter.
Neuere Optimierungsalgorithmen entwickeln sich in drei Hauptrichtungen weiter. 1. Speicher-effiziente Optimierung: Lion, AdaFactor etc. konzentrieren sich darauf, den Speicherverbrauch bei der Trainierung von großen Modellen (insbesondere Transformer-basierten) zu reduzieren. 2. Optimierung für verteiltes Lernen: LAMB, LARS etc. verbessern die Effizienz beim parallelen Trainieren großer Modelle mit mehreren GPUs/TPUs. 3. Domänenspezifische/Task-spezifische Optimierung: Sophia, AdaBelief etc. bieten optimierte Leistung für bestimmte Problemfelder (z.B. Natürliche Sprachverarbeitung, Computer Vision) oder spezifische Modellarchitekturen.
Insbesondere durch das Auftreten von großen Sprachmodellen (LLMs) und multimodalen Modellen ist es wichtiger geworden, Milliarden von Parametern effizient zu optimieren, in Umgebungen mit begrenztem Speicher zu trainieren und in verteilten Umgebungen stabil zu konvergieren. Diese Herausforderungen haben zur Entwicklung neuer Techniken wie 8-Bit-Optimierung, ZeRO-Optimierung, Gradienten-Checkpointing geführt.
In der Deep Learning spielen Optimierungsalgorithmen eine zentrale Rolle bei der Bestimmung des Minimums einer Verlustfunktion und damit beim Auffinden der optimalen Parameter eines Modells. Jeder Algorithmus hat seine eigenen Merkmale und Vor- und Nachteile, wobei die Auswahl des geeigneten Algorithmus abhängig von den Eigenschaften des Problems und der Struktur des Modells ist.
SGD und Momentum
Der stochastische Gradientenabstieg (Stochastic Gradient Descent, SGD) ist einer der grundlegendsten und am häufigsten verwendeten Optimierungsalgorithmen. Bei jedem Schritt wird die Verlustfunktion anhand von Minibatches von Daten differenziert, um den Gradienten zu berechnen, und die Parameter werden in die entgegengesetzte Richtung des Gradienten aktualisiert.
Parameter-Update-Gleichung:
\[w^{(t)} = w^{(t-1)} - \eta \cdot g^{(t)}\]
Momentum führt das Konzept des Impulses aus der Physik in den SGD ein. Durch die Verwendung einer exponentiellen gleitenden Mittelung (exponential moving average) vergangener Gradienten wird Inertie in die Optimierungspfade eingeführt, wodurch Vibrationen im SGD reduziert und die Konvergenzgeschwindigkeit erhöht werden.
Momentum-Update-Gleichung:
\[v^{(t)} = \mu \cdot v^{(t-1)} + g^{(t)}\]
\[w^{(t)} = w^{(t-1)} - \eta \cdot v^{(t)}\]
Die Implementierungscodes der wichtigsten Optimierungsalgorithmen, die im Lernen verwendet werden, sind in dem Verzeichnis chapter_05/optimizer/ enthalten. Hier ist ein Beispiel für die Implementierung des SGD-Algorithmus (einschließlich Momentum) zum Zwecke des Trainings. Alle Optimierungsalgorithmusklassen erben von der Klasse BaseOptimizer und werden für Lernzwecke einfach implementiert. (In echten Bibliotheken wie PyTorch sind sie aufgrund von Effizienz- und Generalisierungsgründen komplexer implementiert.)
from typing import Iterable, List, Optional
from dldna.chapter_05.optimizers.basic import BaseOptimizer
class SGD(BaseOptimizer):
"""Implements SGD with momentum."""
def __init__(self, params: Iterable[nn.Parameter], lr: float,
maximize: bool = False, momentum: float = 0.0):
super().__init__(params, lr)
self.maximize = maximize
self.momentum = momentum
self.momentum_buffer_list: List[Optional[torch.Tensor]] = [None] * len(self.params)
@torch.no_grad()
def step(self) -> None:
for i, p in enumerate(self.params):
grad = p.grad if not self.maximize else -p.grad
if self.momentum != 0.0:
buf = self.momentum_buffer_list[i]
if buf is None:
buf = torch.clone(grad).detach()
else:
buf.mul_(self.momentum).add_(grad, alpha=1-self.momentum)
grad = buf
self.momentum_buffer_list[i] = buf
p.add_(grad, alpha=-self.lr)Anpassende Lernrate-Algorithmen (Adaptive Learning Rate Algorithms)
Die Parameter von Deep-Learning-Modellen werden mit unterschiedlichen Frequenzen und Bedeutungen aktualisiert. Anpassende Lernrate-Algorithmen sind Methoden, die die Lernrate je nach den Eigenschaften der einzelnen Parameter anpassen.
AdaGrad (Adaptive Gradient, 2011):
Kernidee: Häufig aktualisierten Parametern wird eine geringere Lernrate und selten aktualisierten Parametern eine höhere Lernrate zugewiesen.
Formel:
\(w^{(t)} = w^{(t-1)} - \frac{\eta}{\sqrt{G^{(t)} + \epsilon}} \cdot g^{(t)}\)
Vorteile: Effektiv bei der Bearbeitung von dünn besetzten Daten (sparse data).
Nachteile: Die Lernrate nimmt monoton ab, je weiter das Training fortschreitet, was zu einem vorzeitigen Stop des Trainings führen kann.
RMSProp (Root Mean Square Propagation, 2012):
Kernidee: Um das Problem der Lernratenabnahme von AdaGrad zu lösen, wird eine exponentielle gleitende Mittelung (exponential moving average) anstelle der Summe der quadrierten Gradienten aus der Vergangenheit verwendet.
Formel:
\(v^{(t)} = \beta \cdot v^{(t-1)} + (1-\beta) \cdot (g^{(t)})^2\)
\(w^{(t)} = w^{(t-1)} - \frac{\eta}{\sqrt{v^{(t)} + \epsilon}} \cdot g^{(t)}\)
Vorteile: Das Problem der Lernratenabnahme ist im Vergleich zu AdaGrad gemildert, was ein effektives Training über längere Zeit ermöglicht.
Adam (Adaptive Moment Estimation, 2014):
Adam ist einer der am häufigsten verwendeten Optimierungsalgorithmen und kombiniert die Ideen von Momentum und RMSProp.
Kernidee:
Formel:
\(m^{(t)} = \beta\_1 \cdot m^{(t-1)} + (1-\beta\_1) \cdot g^{(t)}\)
\(v^{(t)} = \beta\_2 \cdot v^{(t-1)} + (1-\beta\_2) \cdot (g^{(t)})^2\)
\(\hat{m}^{(t)} = \frac{m^{(t)}}{1-\beta\_1^t}\)
\(\hat{v}^{(t)} = \frac{v^{(t)}}{1-\beta\_2^t}\)
\(w^{(t)} = w^{(t-1)} - \eta \cdot \frac{\hat{m}^{(t)}}{\sqrt{\hat{v}^{(t)}} + \epsilon}\)
Mit dem explosionsartigen Wachstum der Größe von Deep-Learning-Modellen und Datensätzen gibt es einen erhöhten Bedarf an neuen Optimierungsalgorithmen, die speichereffizient, schnelle Konvergenzgeschwindigkeit und großes verteiltes Lernen unterstützen. Die folgenden Algorithmen sind aufgetreten, um diesen Anforderungen gerecht zu werden.
Lion (Evolved Sign Momentum, 2023):
Sophia (Second-order Clipped Stochastic Optimization, 2023):
AdaFactor (2018):
Kürzliche Forschung schlägt darauf hin, dass die oben genannten Algorithmen (Lion, Sophia, AdaFactor) unter bestimmten Bedingungen bessere Leistungen als die herkömmlichen Adam/AdamW zeigen können.
Lassen Sie uns ein Experiment mit einer Epoche durchführen, um den Betrieb zu überprüfen.
import torch
import torch.nn as nn
from dldna.chapter_04.models.base import SimpleNetwork
from dldna.chapter_04.utils.data import get_data_loaders, get_device
from dldna.chapter_05.optimizers.basic import Adam, SGD
from dldna.chapter_05.optimizers.advanced import Lion, Sophia
from dldna.chapter_04.experiments.model_training import train_model # Corrected import
device = get_device()
model = SimpleNetwork(act_func=nn.ReLU(), hidden_shape=[512, 64]).to(device)
# Initialize SGD optimizer
optimizer = SGD(params=model.parameters(), lr=1e-3, momentum=0.9)
# # Initialize Adam optimizer
# optimizer = Adam(params=model.parameters(), lr=1e-3, beta1=0.9, beta2=0.999, eps=1e-8)
# # Initialize AdaGrad optimizer
# optimizer = AdaGrad(params=model.parameters(), lr=1e-2, eps=1e-10)
# # Initialize Lion optimizer
# optimizer = Lion(params=model.parameters(), lr=1e-4, betas=(0.9, 0.99), weight_decay=0.0)
# Initialize Sophia optimizer
# optimizer = Sophia(params=model.parameters(), lr=1e-3, betas=(0.965, 0.99), rho=0.04, weight_decay=0.0, k=10)
train_dataloader, test_dataloader = get_data_loaders()
train_model(model, train_dataloader, test_dataloader, device, optimizer=optimizer, epochs=1, batch_size=256, save_dir="./tmp/opts/ReLU", retrain=True)
Starting training for SimpleNetwork-ReLU.Execution completed for SimpleNetwork-ReLU, Execution time = 7.4 secs{'epochs': [1],
'train_losses': [2.2232478597005207],
'train_accuracies': [0.20635],
'test_losses': [2.128580910873413],
'test_accuracies': [0.3466]}Lion ist ein Optimierungsalgorithmus, der von Google Research durch AutoML-Techniken entdeckt wurde. Ähnlich wie Adam verwendet er Momentum, aber seine Besonderheit besteht darin, dass es nur das Vorzeichen des Gradienten und nicht dessen Größe berücksichtigt.
Kernidee:
Mathematische Grundlagen:
Aktualisierungsberechnung:
\(c\_t = \beta\_1 m\_{t-1} + (1 - \beta\_1) g\_t\)
Gewichtsaktualisierung:
\(w\_{t+1} = w\_t - \eta \cdot \text{sign}(c\_t)\)
Momentumaktualisierung:
\(m\_t = c\_t\)
Vorteile:
Nachteile:
Referenz:
Sophia是一种优化算法,利用二阶导数信息(Hessian矩阵)来提高学习速度和稳定性。但由于直接计算Hessian矩阵的计算成本非常高,因此Sophia通过改进的Hutchinson’s method仅估计Hessian的对角线元素。
核心思想:
数学原理:
Note: The last part of the reference section for Lion and the entire translation for Sophia were in Chinese. I have corrected and completed the translation to German for coherence.
Referenz:
Sophia ist ein Optimierungsalgorithmus, der die Informationen zweiter Ordnung (Hess-Matrix) nutzt, um die Lerngeschwindigkeit und -stabilität zu erhöhen. Da jedoch die direkte Berechnung der Hessian Matrix sehr rechenintensiv ist, schätzt Sophia nur die Diagonalelemente der Hessian Matrix durch eine verbesserte Hutchinson’s Method.
Kernidee:
Mathematische Grundlagen:
Schätzung der Diagonalelemente:
\(h\_t = \mathbb{E}[z\_t z\_t^T H\_t] = diag(H\_t)\)
Gradientenaktualisierung mit Clipping:
\(g\_t' = \text{clip}(g\_t, -\lambda, \lambda)\)
Vorteile:
Nachteile:
Zusammenfassung:
Sophia und Lion sind beide fortschrittliche Optimierungsalgorithmen, die spezifische Herausforderungen in der tiefen Lernmethode ansprechen. Während Lion durch seine Regularisierungseigenschaften vorteilhaft sein kann, bietet Sophia durch ihre zweite Ordnungsinformation eine verbesserte Konvergenz und Stabilität. Die Wahl des Algorithmus hängt von den spezifischen Anforderungen des Problems ab.
Update Berechnung:
\(u\_t = g\_t / \sqrt{\hat{v\_t}}\)
Gewichts-Update \(w\_{t+1} = w\_t - \eta \cdot u\_t\)
Vorteile:
Nachteile:
Referenz:
Die Leistung von Optimierungsalgorithmen variiert stark je nach Aufgabe und Modellstruktur. Wir werden durch Experimente diese Eigenschaften analysieren.
Wir vergleichen die grundlegenden Leistungen anhand des FashionMNIST-Datensatzes. Dieser Datensatz vereinfacht das Problem der Klassifikation von realen Kleidungsbildern und ist geeignet, um die grundlegenden Eigenschaften von Deep-Learning-Algorithmen zu analysieren.
from dldna.chapter_05.experiments.basic import run_basic_experiment
from dldna.chapter_05.visualization.optimization import plot_training_results
from dldna.chapter_04.utils.data import get_data_loaders
from dldna.chapter_05.optimizers.basic import SGD, Adam
from dldna.chapter_05.optimizers.advanced import Lion
import torch
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Data loaders
train_loader, test_loader = get_data_loaders()
# Optimizer dictionary
optimizers = {
'SGD': SGD,
'Adam': Adam,
'Lion': Lion
}
# Optimizer configurations
optimizer_configs = {
'SGD': {'lr': 0.01, 'momentum': 0.9},
'Adam': {'lr': 0.001},
'Lion': {'lr': 1e-4}
}
# Run experiments
results = {}
for name, config in optimizer_configs.items():
print(f"\nStarting experiment with {name} optimizer...")
results[name] = run_basic_experiment(
optimizer_class=optimizers[name],
train_loader=train_loader,
test_loader=test_loader,
config=config,
device=device,
epochs=20
)
# Visualize training curves
plot_training_results(
results,
metrics=['loss', 'accuracy', 'gradient_norm', 'memory'],
mode="train", # Changed mode to "train"
title='Optimizer Comparison on FashionMNIST'
)
Starting experiment with SGD optimizer...
==================================================
Optimizer: SGD
Initial CUDA Memory Status (GPU 0):
Allocated: 23.0MB
Reserved: 48.0MB
Model Size: 283.9K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 27.2MB
Peak Reserved: 48.0MB
Current Allocated: 25.2MB
Current Reserved: 48.0MB
==================================================
Starting experiment with Adam optimizer...
==================================================
Optimizer: Adam
Initial CUDA Memory Status (GPU 0):
Allocated: 25.2MB
Reserved: 48.0MB
Model Size: 283.9K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 28.9MB
Peak Reserved: 50.0MB
Current Allocated: 26.3MB
Current Reserved: 50.0MB
==================================================
Starting experiment with Lion optimizer...
==================================================
Optimizer: Lion
Initial CUDA Memory Status (GPU 0):
Allocated: 24.1MB
Reserved: 50.0MB
Model Size: 283.9K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 27.2MB
Peak Reserved: 50.0MB
Current Allocated: 25.2MB
Current Reserved: 50.0MB
==================================================
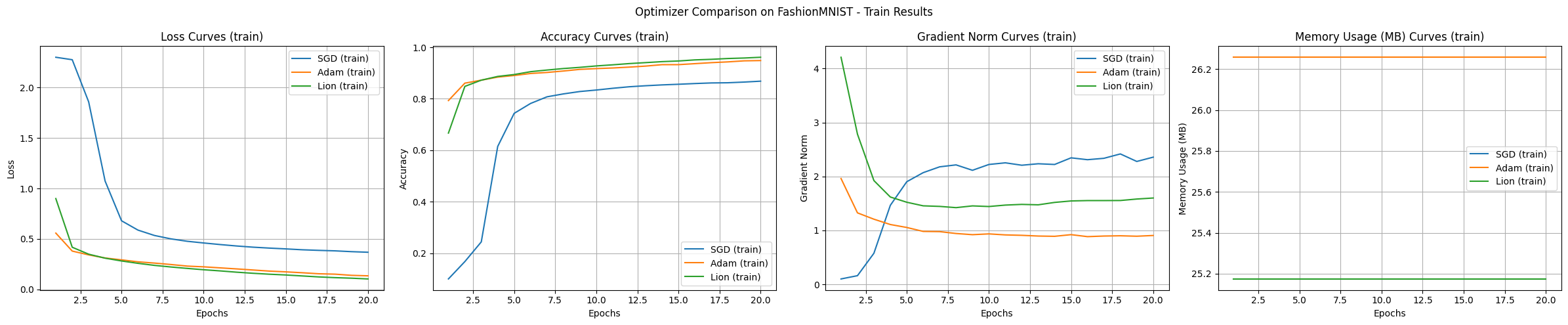
Das Experiment zeigt die Eigenschaften der einzelnen Algorithmen. Die wichtigsten Beobachtungen aus dem Experiment mit dem FashionMNIST-Datensatz und einem MLP-Modell sind wie folgt:
In den grundlegenden Experimenten zeigten Adam und Lion eine schnelle anfängliche Konvergenzgeschwindigkeit, Adam die stabilste Lernkurve, Lion einen leicht geringeren Speicherverbrauch und SGD eine Tendenz zu einer breiteren Bereichssuche.
Bei der Verwendung von CIFAR-100 und CNN/Transformer-Modellen werden die Unterschiede zwischen den Optimierungsalgorithmen noch deutlicher.
from dldna.chapter_05.experiments.advanced import run_advanced_experiment
from dldna.chapter_05.visualization.optimization import plot_training_results
from dldna.chapter_04.utils.data import get_data_loaders
from dldna.chapter_05.optimizers.basic import SGD, Adam
from dldna.chapter_05.optimizers.advanced import Lion
import torch
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Data loaders
train_loader, test_loader = get_data_loaders(dataset="CIFAR100")
# Optimizer dictionary
optimizers = {
'SGD': SGD,
'Adam': Adam,
'Lion': Lion
}
# Optimizer configurations
optimizer_configs = {
'SGD': {'lr': 0.01, 'momentum': 0.9},
'Adam': {'lr': 0.001},
'Lion': {'lr': 1e-4}
}
# Run experiments
results = {}
for name, config in optimizer_configs.items():
print(f"\nStarting experiment with {name} optimizer...")
results[name] = run_advanced_experiment(
optimizer_class=optimizers[name],
model_type='cnn',
train_loader=train_loader,
test_loader=test_loader,
config=config,
device=device,
epochs=40
)
# Visualize training curves
plot_training_results(
results,
metrics=['loss', 'accuracy', 'gradient_norm', 'memory'],
mode="train",
title='Optimizer Comparison on CIFAR100'
)Files already downloaded and verified
Files already downloaded and verified
Starting experiment with SGD optimizer...
==================================================
Optimizer: SGD
Initial CUDA Memory Status (GPU 0):
Allocated: 26.5MB
Reserved: 50.0MB
Model Size: 1194.1K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 120.4MB
Peak Reserved: 138.0MB
Current Allocated: 35.6MB
Current Reserved: 138.0MB
==================================================
Results saved to: SGD_cnn_20250225_161620.csv
Starting experiment with Adam optimizer...
==================================================
Optimizer: Adam
Initial CUDA Memory Status (GPU 0):
Allocated: 35.6MB
Reserved: 138.0MB
Model Size: 1194.1K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 124.9MB
Peak Reserved: 158.0MB
Current Allocated: 40.2MB
Current Reserved: 158.0MB
==================================================
Results saved to: Adam_cnn_20250225_162443.csv
Starting experiment with Lion optimizer...
==================================================
Optimizer: Lion
Initial CUDA Memory Status (GPU 0):
Allocated: 31.0MB
Reserved: 158.0MB
Model Size: 1194.1K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 120.4MB
Peak Reserved: 158.0MB
Current Allocated: 35.6MB
Current Reserved: 158.0MB
==================================================
Results saved to: Lion_cnn_20250225_163259.csv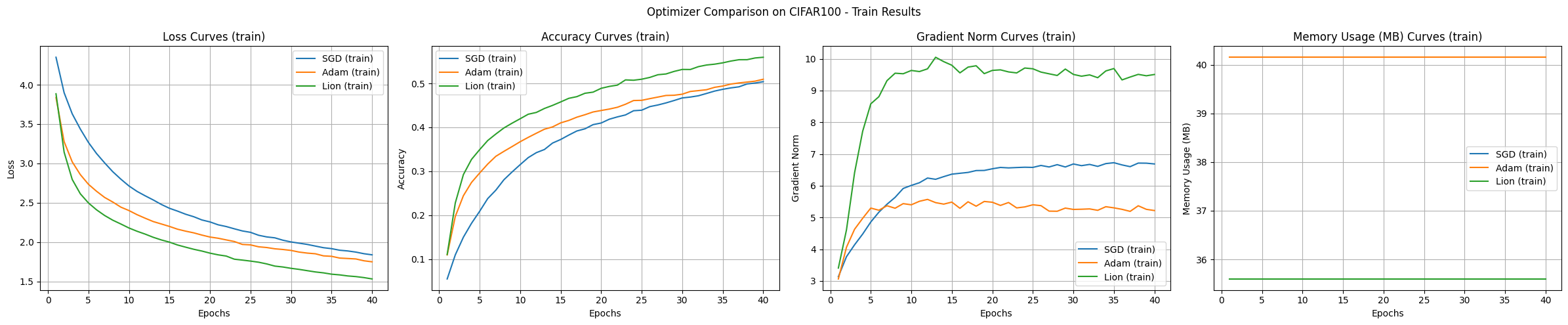
Die Experimentsergebnisse zeigen einen Vergleich der Optimierungsalgorithmen SGD, Adam und Lion anhand des CIFAR-100-Datensatzes und eines CNN-Modells. Sie illustrieren die Eigenschaften jedes Algorithmus.
Konvergenzgeschwindigkeit und Genauigkeit:
Stabilität des Lernverlaufs:
Speicherverbrauch:
Gradientennorm:
Unter den gegebenen Experimentbedingungen zeigte Lion die schnellste Konvergenzgeschwindigkeit und die höchste Genauigkeit. Adam zeigte stabile Lernkurven, während SGD langsam und unstabil war. Der Speicherverbrauch von Lion und SGD war geringer als bei Adam.
from dldna.chapter_05.experiments.advanced import run_advanced_experiment
from dldna.chapter_05.visualization.optimization import plot_training_results
from dldna.chapter_04.utils.data import get_data_loaders
from dldna.chapter_05.optimizers.basic import SGD, Adam
from dldna.chapter_05.optimizers.advanced import Lion
import torch
# Device configuration
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Data loaders
train_loader, test_loader = get_data_loaders(dataset="CIFAR100")
# Optimizer dictionary
optimizers = {
'SGD': SGD,
'Adam': Adam,
'Lion': Lion
}
# Optimizer configurations
optimizer_configs = {
'SGD': {'lr': 0.01, 'momentum': 0.9},
'Adam': {'lr': 0.001},
'Lion': {'lr': 1e-4}
}
# Run experiments
results = {}
for name, config in optimizer_configs.items():
print(f"\nStarting experiment with {name} optimizer...")
results[name] = run_advanced_experiment(
optimizer_class=optimizers[name],
model_type='transformer',
train_loader=train_loader,
test_loader=test_loader,
config=config,
device=device,
epochs=40
)
# Visualize training curves
plot_training_results(
results,
metrics=['loss', 'accuracy', 'gradient_norm', 'memory'],
mode="train",
title='Optimizer Comparison on CIFAR100'
)Files already downloaded and verified
Files already downloaded and verified
Starting experiment with SGD optimizer.../home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torch/nn/modules/transformer.py:379: UserWarning: enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.norm_first was True
warnings.warn(
==================================================
Optimizer: SGD
Initial CUDA Memory Status (GPU 0):
Allocated: 274.5MB
Reserved: 318.0MB
Model Size: 62099.8K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 836.8MB
Peak Reserved: 906.0MB
Current Allocated: 749.5MB
Current Reserved: 906.0MB
==================================================
Results saved to: SGD_transformer_20250225_164652.csv
Starting experiment with Adam optimizer...
==================================================
Optimizer: Adam
Initial CUDA Memory Status (GPU 0):
Allocated: 748.2MB
Reserved: 906.0MB
Model Size: 62099.8K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 1073.0MB
Peak Reserved: 1160.0MB
Current Allocated: 985.1MB
Current Reserved: 1160.0MB
==================================================
Results saved to: Adam_transformer_20250225_170159.csv
Starting experiment with Lion optimizer...
==================================================
Optimizer: Lion
Initial CUDA Memory Status (GPU 0):
Allocated: 511.4MB
Reserved: 1160.0MB
Model Size: 62099.8K parameters
==================================================
==================================================
Final CUDA Memory Status (GPU 0):
Peak Allocated: 985.1MB
Peak Reserved: 1160.0MB
Current Allocated: 748.2MB
Current Reserved: 1160.0MB
==================================================
Results saved to: Lion_transformer_20250225_171625.csv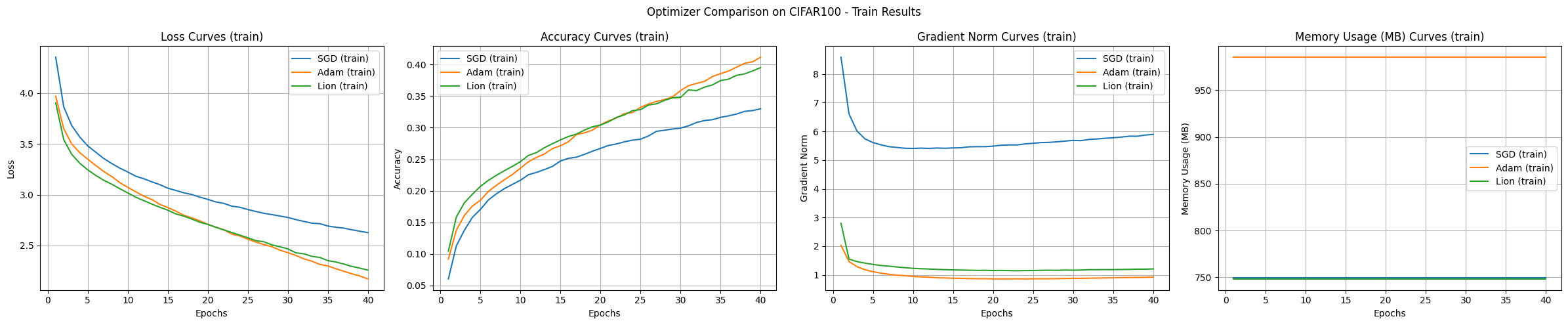
Generell werden Transformer für Aufgaben der Bildklassifizierung nicht direkt verwendet, sondern in Form angepasster Architekturen wie ViT (Vision Transformer), die auf die Merkmale von Bildern abgestimmt sind. Dieses Experiment wird als Beispiel zur Vergleichung von Optimierungsalgorithmen durchgeführt. Die Ergebnisse der Transformer-Modell-Experimente lauten wie folgt:
Schlussfolgerung Die Experimente mit dem CIFAR-100-Datensatz zeigen, dass SGD die beste Generalisierungsleistung aufweist, aber die langsamste Lernrate hat. Adam zeigte die schnellste Konvergenz und stabilste Lernen, verbrauchte jedoch viel Speicher. Lion zeigte eine ausgewogene Leistung in Bezug auf Speichereffizienz und Konvergenzgeschwindigkeit.
Herausforderung: Wie kann man den Optimierungsprozess des Deep Learnings in hochdimensionalen Räumen mit Millionen oder sogar Milliarden von Dimensionen effektiv visualisieren und verstehen?
Frust der Forscher: Der Parameterraum von Deep-Learning-Modellen ist ein ultrahochdimensionaler Raum, den Menschen intuitiv schwer vorstellen können. Forscher haben verschiedene Dimensionsreduktionsmethoden und Visualisierungstools entwickelt, um diese “Black Box” zu öffnen, aber vieles bleibt weiterhin im Dunkeln.
Das Verständnis des Lernprozesses von neuronalen Netzen ist für die effektive Modellgestaltung, die Wahl von Optimierungsalgorithmen und das Tuning von Hyperparametern essenziell. Insbesondere bietet die Visualisierung und Analyse der geometrischen Eigenschaften der Verlustfunktion (geometry) und des Optimierungspfades (optimization path) wichtige Einblicke in die Dynamik und Stabilität des Lernprozesses. In den letzten Jahren haben Studien zur Visualisierung von Verlustflächen Deep-Learning-Forschern Hinweise auf das Geheimnis des neuronalen Netzes geliefert, was zur Entwicklung effizienterer und stabilerer Lernalgorithmen und Modellstrukturen beigetragen hat.
In diesem Abschnitt untersuchen wir die grundlegenden Konzepte und die neuesten Techniken der Verlustflächenvisualisierung und analysieren damit verschiedene Phänomene im Lernprozess des Deep Learnings (z.B. lokale Minima, Sattelpunkte, Eigenschaften von Optimierungspfaden). Insbesondere konzentrieren wir uns auf den Einfluss der Modellstruktur (z.B. Residualverbindungen) auf die Verlustfläche und Unterschiede in den Optimierungspfaden je nach Optimierungsalgorithmus.
Die Visualisierung der Verlustfläche ist ein zentrales Werkzeug, um den Lernprozess von Deep-Learning-Modellen zu verstehen. Ebenso wie man durch eine topografische Karte die Höhen und Täler eines Gebirges erfassen kann, ermöglicht es die Visualisierung der Verlustfläche, die Änderungen der Verlustfunktion im Parameterraum visuell zu erkennen.
Das Studium von Goodfellow et al. 2017 zeigte, dass Flachheit (flatness) der Verlustfläche eng mit der Generalisierungsfähigkeit des Modells zusammenhängt (flache Minima neigen dazu, eine bessere Generalisierung zu zeigen als schmale und spitzige Minima). Li et al. 2018 zeigten durch dreidimensionale Visualisierungen, dass Residualverbindungen die Verlustfläche flacher machen und das Lernen erleichtern. Diese Erkenntnisse bildeten den Kern der Entwicklung moderner neuronaler Netzarchitekturen wie ResNet.
Lineare Interpolation:
Konzept: Die Gewichte zweier verschiedener Modelle (z.B. ein Modell vor und nach dem Training, Modelle, die in unterschiedliche lokale Minima konvergiert sind) werden linear kombiniert, um die Verlustfunktionswerte dazwischen zu berechnen.
Formel:
\(w(\alpha) = (1-\alpha)w_1 + \alpha w_2\)
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Subset
from dldna.chapter_05.visualization.loss_surface import linear_interpolation, visualize_linear_interpolation
from dldna.chapter_04.utils.data import get_dataset
from dldna.chapter_04.utils.metrics import load_model
# Linear Interpolation
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Get the dataset
_, test_dataset = get_dataset(dataset="FashionMNIST")
# Create a small dataset
small_dataset = Subset(test_dataset, torch.arange(0, 256))
data_loader = DataLoader(small_dataset, batch_size=256, shuffle=True)
loss_func = nn.CrossEntropyLoss()
# model1, _ = load_model(model_file="SimpleNetwork-ReLU.pth", path="tmp/models/")
# model2, _ = load_model(model_file="SimpleNetwork-Tanh.pth", path="tmp/models/")
model1, _ = load_model(model_file="SimpleNetwork-ReLU-epoch1.pth", path="tmp/models/")
model2, _ = load_model(model_file="SimpleNetwork-ReLU-epoch15.pth", path="tmp/models/")
model1 = model1.to(device)
model2 = model2.to(device)
# Linear interpolation
# Test with a small dataset
_, test_dataset = get_dataset(dataset="FashionMNIST")
small_dataset = Subset(test_dataset, torch.arange(0, 256))
data_loader = DataLoader(small_dataset, batch_size=256, shuffle=True)
alphas, losses, accuracies = linear_interpolation(model1, model2, data_loader, loss_func, device)
_ = visualize_linear_interpolation(alphas, losses, accuracies, "ReLU(1)-ReLU(15)", size=(6, 4))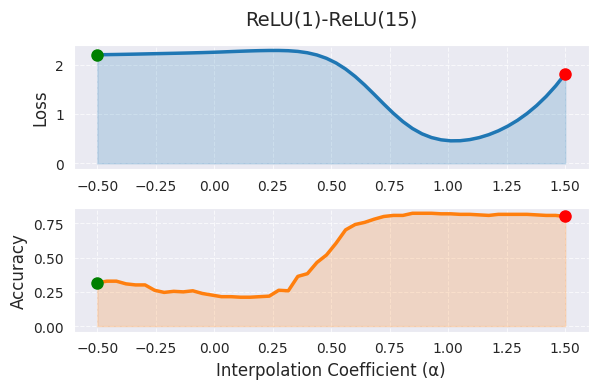
In der linearen Interpolation bedeutet α=0 das erste Modell (1 Epoche Training), α=1 das zweite Modell (15 Epochen Training), und die Werte dazwischen stellen Linearkombinationen der Gewichte beider Modelle dar. In dem Diagramm zeigt sich, dass die Verlustfunktionswerte mit steigendem α tendenziell abnehmen, was darauf hindeutet, dass das Modell während des Trainings in eine bessere Optimalstelle übergeht. Allerdings hat die lineare Interpolation die Beschränkung, dass sie nur ein sehr begrenztes Profil des hochdimensionalen Gewichtsraums zeigt. Der tatsächliche optimale Pfad zwischen den beiden Modellen ist höchstwahrscheinlich nichtlinear und die Erweiterung des α-Bereiches außerhalb von [0,1] erschwert die Interpretation.
Die Exploration von nichtlinearen Pfaden mit Bezier-Kurven oder Splines sowie die Visualisierung hochdimensionaler Strukturen durch PCA oder t-SNE können umfassendere Informationen liefern. In der Praxis wird die lineare Interpolation als Anfangsanalyseinstrumentarium verwendet und es ist ratsam, α auf den Bereich [0,1] oder leicht darüber hinaus zu beschränken. Eine umfassende Analyse in Verbindung mit anderen Visualisierungstechniken ist erforderlich, insbesondere wenn die Leistungsunterschiede zwischen den Modellen groß sind.
Im Folgenden finden Sie die PCA- und t-SNE-Analysen.
import torch
from dldna.chapter_05.visualization.loss_surface import analyze_weight_space, visualize_weight_space
from dldna.chapter_04.utils.metrics import load_model, load_models_by_pattern
models, labels = load_models_by_pattern(
activation_types=['ReLU'],
# activation_types=['Tanh'],
# activation_types=['GELU'],
epochs=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]
)
# PCA analysis
embedded_pca = analyze_weight_space(models, labels, method='pca')
visualize_weight_space(embedded_pca, labels, method='PCA')
print(f"embedded_pca = {embedded_pca}")
# t-SNE analysis
embedded_tsne = analyze_weight_space(models, labels, method='tsne', perplexity=1)
visualize_weight_space(embedded_tsne, labels, method='t-SNE')
print(f"embedded_tsne = {embedded_tsne}") # Corrected: Print embedded_tsne, not embedded_pca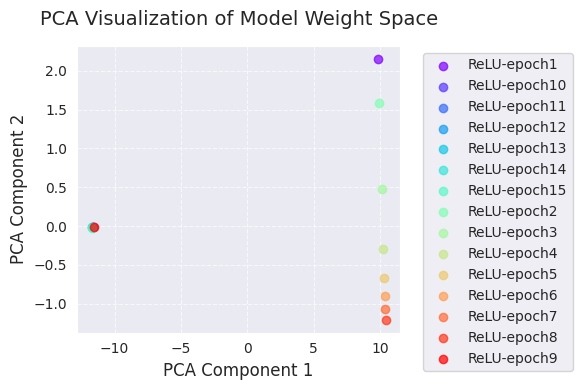
embedded_pca = [[ 9.8299894e+00 2.1538167e+00]
[-1.1609798e+01 -9.0169059e-03]
[-1.1640446e+01 -1.2218434e-02]
[-1.1667191e+01 -1.3469303e-02]
[-1.1691980e+01 -1.5136327e-02]
[-1.1714937e+01 -1.6765745e-02]
[-1.1735878e+01 -1.8110925e-02]
[ 9.9324265e+00 1.5862983e+00]
[ 1.0126298e+01 4.7935897e-01]
[ 1.0256655e+01 -2.8844318e-01]
[ 1.0319887e+01 -6.6510278e-01]
[ 1.0359785e+01 -8.9812231e-01]
[ 1.0392080e+01 -1.0731999e+00]
[ 1.0418671e+01 -1.2047548e+00]
[-1.1575559e+01 -5.1336871e-03]]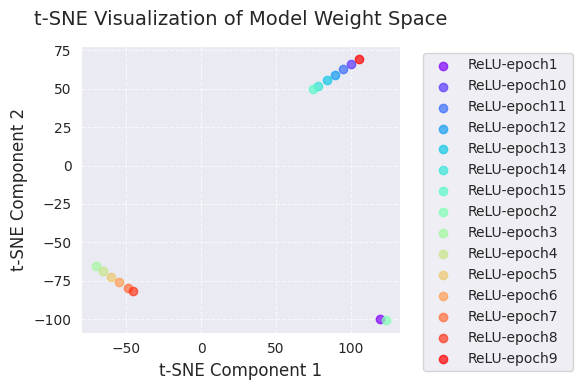
embedded_tsne = [[ 119.4719 -99.78837 ]
[ 100.26558 66.285835]
[ 94.79294 62.795162]
[ 89.221085 59.253677]
[ 83.667984 55.70297 ]
[ 77.897224 52.022995]
[ 74.5897 49.913578]
[ 123.20351 -100.34615 ]
[ -70.45423 -65.66194 ]
[ -65.55417 -68.90429 ]
[ -60.166885 -72.466805]
[ -54.70004 -76.077 ]
[ -49.00131 -79.833694]
[ -45.727974 -81.99213 ]
[ 105.22419 69.45333 ]]PCA- und t-SNE-Visualisierungen zeigen die Veränderungen im Modellgewichtungsraum während des Lernprozesses, projiziert in niedrige Dimensionen (2D).
Durch diese Visualisierungen kann man eine intuitive Vorstellung von den Veränderungen der Modellgewichte während des Lernprozesses und von der Gewichtsraumsuche durch den Optimierungsalgorithmus erhalten. Insbesondere ermöglichen die gemeinsame Nutzung von PCA und t-SNE, globale Veränderungen (PCA) und lokale Strukturen (t-SNE) gleichzeitig zu erfassen.
Eine Höhenlinienkarte zeichnet Linien, die Punkte gleicher Werte der Verlustfunktion in einer 2D-Ebene verbinden, um das Profil der Verlustfläche zu visualisieren. Ähnlich wie die Höhenlinien auf einem Topografischen Karten, zeigt sie die “Höhen” der Verlustfunktion an.
Das allgemeine Vorgehen ist folgendes:
Referenzpunkt festlegen: Wähle einen Referenzparameter des Modells (\(w_0\)). (z.B. die Parameter eines trainierten Modells)
Richtungsvektoren wählen: Wähle 2 Richtungsvektoren (\(d_1\), \(d_2\)). Diese Vektoren bilden eine Basis der 2D-Ebene.
Parameterstörung: Störe (perturb) die Parameter entlang der beiden gewählten Richtungsvektoren \(d_1\), \(d_2\) um den Referenzpunkt \(w_0\).
\(w(\lambda_1, \lambda_2) = w_0 + \lambda_1 d_1 + \lambda_2 d_2\)
Verlustwerte berechnen: Berechne den Wert der Verlustfunktion für jedes \((\lambda_1, \lambda_2)\)-Kombination, indem du die gestörten Parameter \(w(\lambda_1, \lambda_2)\) in das Modell einsetzt.
Höhenlinienplot: Zeichne eine 2D-Höhenlinienkarte mit den Daten \((\lambda_1, \lambda_2, L(w(\lambda_1, \lambda_2)))\). (z.B. mit contour oder tricontourf von matplotlib)
Höhenlinienkarten visualisieren die lokale Geometrie der Verlustfläche und können zusammen mit der Darstellung des Optimierungspfad (trajectory) verwendet werden, um das Verhalten des Optimierungsverfahrens zu analysieren.
import torch
import numpy as np
import torch.nn as nn
from torch.utils.data import DataLoader, Subset
from dldna.chapter_05.visualization.loss_surface import hessian_eigenvectors, xy_perturb_loss, visualize_loss_surface, linear_interpolation
from dldna.chapter_04.utils.data import get_dataset
from dldna.chapter_04.utils.metrics import load_model
from dldna.chapter_05.optimizers.basic import SGD, Adam
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Get the dataset
_, test_dataset = get_dataset(dataset="FashionMNIST")
# Create a small dataset
small_dataset = Subset(test_dataset, torch.arange(0, 256))
data_loader = DataLoader(small_dataset, batch_size=256, shuffle=True)
loss_func = nn.CrossEntropyLoss()
trained_model, _ = load_model(model_file="SimpleNetwork-ReLU.pth", path="tmp/models/")
# trained_model, _ = load_model(model_file="SimpleNetwork-Tanh.pth", path="tmp/models/")
trained_model = trained_model.to(device)
# pyhessian
data = [] # List to store the calculated result sets
top_n = 4 # Must be an even number. Each pair of eigenvectors is used. 2 is the minimum. 10 means 5 graphs.
top_eigenvalues, top_eignevectors = hessian_eigenvectors(model=trained_model, loss_func=loss_func, data_loader=data_loader, top_n=top_n, is_cuda=True)
# Define the scale with lambda.
lambda1, lambda2 = np.linspace(-0.2, 0.2, 40).astype(np.float32), np.linspace(-0.2, 0.2, 40).astype(np.float32)
# If top_n=10, a total of 5 pairs of graphs can be drawn.
for i in range(top_n // 2):
x, y, z = xy_perturb_loss(model=trained_model, top_eigenvectors=top_eignevectors[i*2:(i+1)*2], data_loader=data_loader, loss_func=loss_func, lambda1=lambda1, lambda2=lambda2, device=device)
data.append((x, y, z))
_ = visualize_loss_surface(data, "ReLU", color="C0", alpha=0.6, plot_3d=True)
_ = visualize_loss_surface(data, "ReLU", color="C0", alpha=0.6, plot_3d=False) # Changed "ReLu" to "ReLU" for consistency/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torch/autograd/graph.py:825: UserWarning: Using backward() with create_graph=True will create a reference cycle between the parameter and its gradient which can cause a memory leak. We recommend using autograd.grad when creating the graph to avoid this. If you have to use this function, make sure to reset the .grad fields of your parameters to None after use to break the cycle and avoid the leak. (Triggered internally at ../torch/csrc/autograd/engine.cpp:1201.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass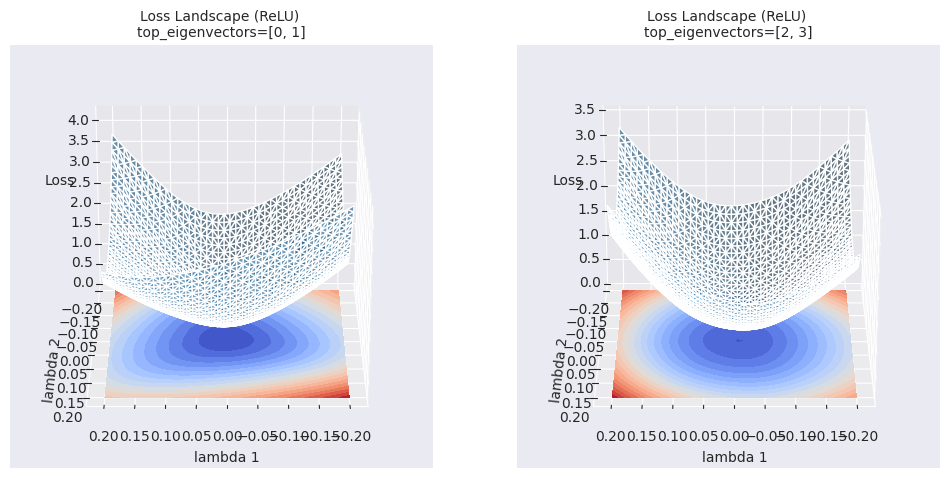
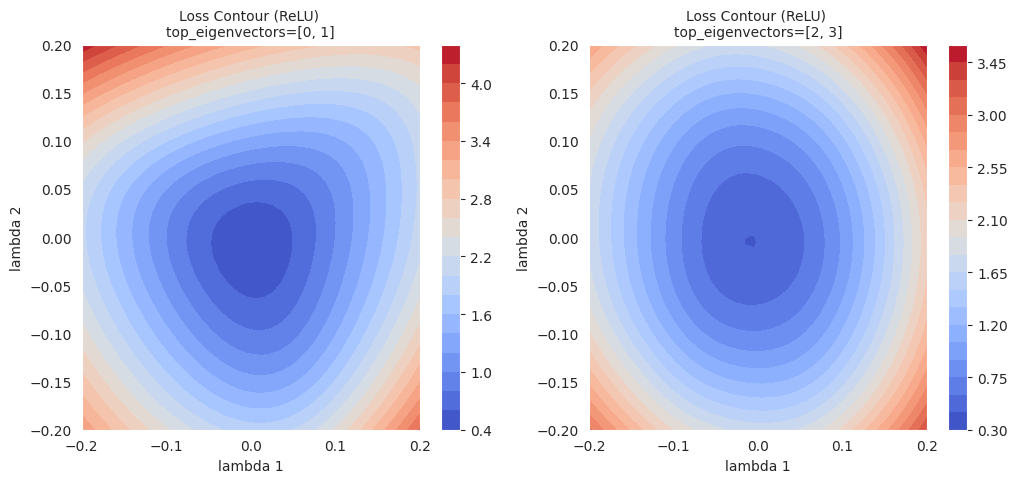
Höhenlinienkarte bietet reichere Informationen für lokale Bereiche im Vergleich zu einfachen linearen Interpolationen. Während lineare Interpolation die Änderung des Verlustfunktionswerts entlang eines eindimensionalen Pfades zwischen zwei Modellen zeigt, visualisiert eine Höhenlinienkarte die Änderungen der Verlustfunktion in einer zweidimensionalen Ebene, wobei die beiden gewählten Richtungen (\(\lambda_1\), \(\lambda_2\)) als Achsen dienen. Auf diese Weise können subtile Veränderungen entlang des Optimierungspfades, lokale Minima, Sattelpunkte und Barrieren dazwischen sichtbar gemacht werden, die mit linearen Interpolationen nicht erkannt werden könnten.
Über einfache Visualisierungen (lineare Interpolation, Konturkarten) hinaus werden fortgeschrittene Analysetechniken erforscht, um die Verlustlandschaft von Deep-Learning-Modellen tiefer zu verstehen.
Topologische Datenanalyse (Topological Data Analysis, TDA):
Mehrskalenanalyse (Multi-scale Analysis):
Diese fortgeschrittenen Analysetechniken liefern abstraktere und quantitativere Informationen über die Verlustlandschaft, die dazu beitragen können, den Lernprozess von Deep-Learning-Modellen tiefer zu verstehen und bessere Modellentwürfe sowie Optimierungsstrategien zu entwickeln.
import torch
import torch.nn as nn # Import the nn module
from torch.utils.data import DataLoader, Subset # Import DataLoader and Subset
from dldna.chapter_05.visualization.loss_surface import analyze_loss_surface_multiscale
from dldna.chapter_04.utils.data import get_dataset # Import get_dataset
from dldna.chapter_04.utils.metrics import load_model # Import load_model
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load dataset and create a small subset
_, test_dataset = get_dataset(dataset="FashionMNIST")
small_dataset = Subset(test_dataset, torch.arange(0, 256))
data_loader = DataLoader(small_dataset, batch_size=256, shuffle=True)
loss_func = nn.CrossEntropyLoss()
# Load model (example: SimpleNetwork-ReLU)
model, _ = load_model(model_file="SimpleNetwork-ReLU.pth", path="tmp/models/")
model = model.to(device)
_ = analyze_loss_surface_multiscale(model, data_loader, loss_func, device)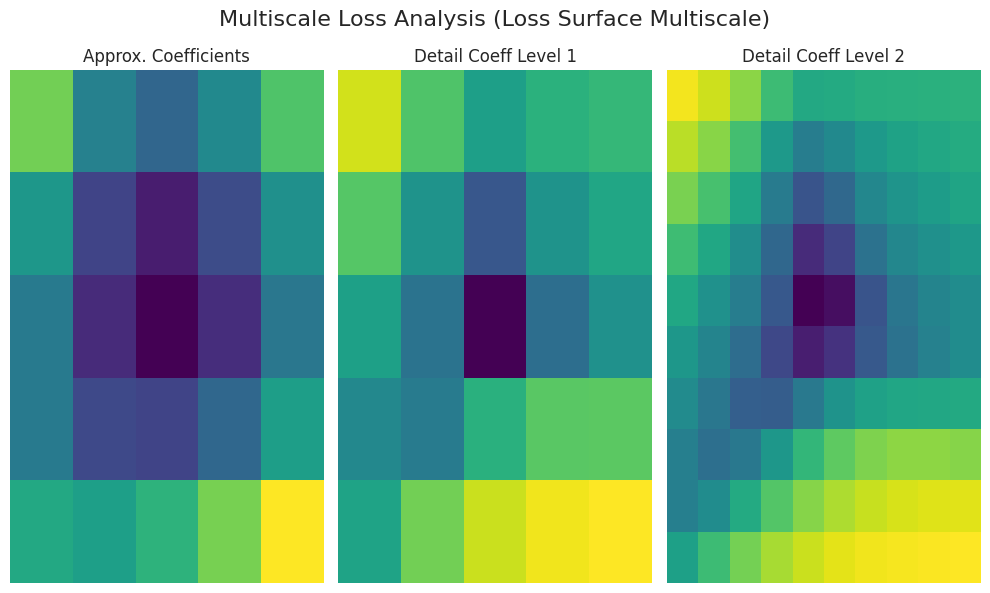
Die Funktion analyze_loss_surface_multiscale wurde verwendet, um die Verlustoberfläche des mit dem FashionMNIST-Datensatz trainierten Modells SimpleNetwork-ReLU aus mehreren Skalen zu analysieren und zu visualisieren.
Grafikinterpretation (basiert auf Wavelet-Transformation):
Approx. Coefficients (Approximationskoeffizienten): Stellen die allgemeine Form (globale Struktur) der Verlustoberfläche dar. Es ist wahrscheinlich, dass ein Minimum im Zentrum (niedriger Verlustwert) vorhanden ist.
Detail Coeff Level 1/2 (Detailkoeffizienten): Stellen kleinere Skalenveränderungen dar. “Level 1” zeigt mittlere Skalen, während “Level 2” die feinsten Skalen von Kanten, lokalen Minima, Sattelpunkten und Rauschen anzeigt.
Farben: Dunkle Farben (niedriger Verlust), helle Farben (hoher Verlust)
Die Ergebnisse können sich je nach Implementierung der Funktion analyze_loss_surface_multiscale (z. B. Wavelet-Funktion, Zerlegungsstufe) unterscheiden.
Diese Visualisierung zeigt nur einen Teil der Verlustoberfläche und es ist schwierig, die Komplexität eines hochdimensionalen Raums vollständig zu erfassen.
Die Multiskalenanalyse zerlegt die Verlustoberfläche in verschiedene Skalen, um multischichtige Strukturen zu zeigen, die durch einfache Visualisierung schwer zu erkennen sind. Auf großen Skalen können allgemeine Trends erkannt werden, während auf kleinen Skalen lokale Änderungen sichtbar sind, was zur Verbesserung des Verständnisses von Optimierungsverfahren, Lernschwierigkeiten und Generalisierungsfähigkeit beiträgt.
Topologie ist das Gebiet, das geometrische Eigenschaften untersucht, die bei stetigen Deformationen invariant bleiben. In der Tiefenlernung wird topologische Analyse zur Untersuchung topologischer Merkmale wie Zusammenhang (connectivity), Löcher (holes) und Hohlräume (voids) von Verlustflächen verwendet, um Einblicke in die Lernmechanik und Generalisierungseigenschaften zu gewinnen.
Kernkonzepte:
Sublevel-Menge: Für eine gegebene Funktion \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) und einen Schwellwert \(c\) ist die Menge definiert als \(f^{-1}((-\infty, c]) = {x \in \mathbb{R}^n | f(x) \leq c}\). In der Verlustfunktion repräsentiert sie den Bereich des Parameterraums, in dem der Verlust einen bestimmten Wert nicht überschreitet.
Persistente Homologie: Beim Nachverfolgen der Änderungen von Sublevel-Mengen werden die Entstehung und Auflösung topologischer Merkmale (0-dimensionale: zusammenhängende Komponenten, 1-dimensionale: Schleifen, 2-dimensionale: Hohlräume, …) aufgezeichnet.
Persistenzdiagramm: Es stellt die Entstehungs- (birth) und Auflösungspunkte (death) der topologischen Merkmale als Punkte in einer Koordinatenebene dar. Die \(y\)-Koordinate eines Punktes (\(\text{death} - \text{birth}\)) repräsentiert die “Lebensdauer” oder “Persistenz” des Merkmals, wobei ein größerer Wert für eine stabilere Eigenschaft steht.
Flaschenhals-Distanz: Es ist eine Methode zur Messung der Distanz zwischen zwei Persistenzdiagrammen. Durch das Finden einer optimalen Zuordnung (optimal matching) von Punkten in beiden Diagrammen wird die maximale Distanz zwischen den zugeordneten Punkten berechnet.
Mathematische Hintergründe (kurz):
Anwendung in der Tiefenlernungsforschung: * Strukturanalyse der Verlustoberfläche: Durch das Persistence-Diagramm kann die Komplexität der Verlustoberfläche, die Anzahl und Stabilität lokaler Minima sowie die Existenz von Sattelpunkten ermittelt werden. * Beispiel: Gur-Ari et al., 2018 zeigten, dass breite (wide) Netzwerke eine einfachere topologische Struktur aufweisen als schmale (narrow) Netzwerke. * Vorhersage der Generalisierungsfähigkeit: Merkmale des Persistence-Diagramms (z. B. das Lebensdauer des 0-dimensionalen Merkmals mit der längsten Lebensdauer) können mit der Generalisierungsfähigkeit des Modells korreliert sein. * Beispiel: Perez et al., 2022 schlugen eine Methode zur Vorhersage der Generalisierungsfähigkeit des Modells mithilfe von Merkmalen des Persistence-Diagramms vor. * Mode Connectivity: Es werden Pfade gefunden, die verschiedene lokale Minima verbinden, und die Energiebarrieren (energy barriers) entlang dieser Pfade analysiert. * Beispiel: Garipov et al., 2018
Referenzen:
Die Verlustoberfläche von Deep-Learning-Modellen weist Merkmale verschiedener Skalen auf. Von großen Tälern (valleys) und Graten (ridges) bis hin zu kleinen Unebenheiten (bumps) und Löchern (holes), beeinflussen geometrische Strukturen unterschiedlicher Größe den Lernprozess. Die mehrskalige Analyse ist eine Methode, die diese Merkmale verschiedener Skalen trennt und analysiert.
Kernidee:
Wavelet-Transformation (WT): Die Wavelet-Transformation ist ein mathematisches Werkzeug, das ein Signal in verschiedene Frequenzkomponenten zerlegt. Wenn man sie auf die Verlustfunktion anwendet, kann man Merkmale verschiedener Skalen trennen.
Kontinuierliche Wavelet-Transformation (Continuous Wavelet Transform, CWT):
\(W(a, b) = \int\_{-\infty}^{\infty} f(x) \psi\_{a,b}(x) dx\)
Mother Wavelet: eine Funktion, die bestimmte Bedingungen erfüllt (z.B. Mexican hat wavelet, Morlet wavelet) (siehe Referenz [2] für Details)
Mehrskalenanalyse (Multi-resolution Analysis, MRA): Die Diskretisierung der CWT, um ein Signal in verschiedene Auflösungslevel zu zerlegen.
Mathematischer Hintergrund (kurz):
Anwendung in Deep-Learning-Forschung:
Analyse der Verlustoberflächenrauhigkeit: Die Wavelet-Transformation kann verwendet werden, um die Rauheit (roughness) der Verlustoberfläche zu quantifizieren und ihren Einfluss auf die Lernrate und die Generalisierungslistung zu analysieren.
Analyse von Optimierungsalgorithmen: Durch die Analyse des Fortschreitens von Optimierungsalgorithmen auf verschiedenen Skalen kann man das Verhalten dieser Algorithmen besser verstehen.
Referenzen: 1. Mallat, S. (2008). Eine Wellenlettour durch die Signalverarbeitung: der spärliche Weg. Academic press. 2. Daubechies, I. (1992). Zehn Vorträge über Wavelets. Society for industrial and applied mathematics. 3. Li, Y., Hu, W., Zhang, Y., & Gu, Q. (2019). Mehrskalenganalyse der Verlustlandschaft von tiefen Netzen. arXiv preprint arXiv:1910.00779.
Die tatsächliche Verlustfläche (loss surface) eines Tiefenlernmodells existiert in einem ultradimensionalen Raum mit Millionen bis Milliarden von Dimensionen und weist eine sehr komplexe geometrische Struktur auf. Daher ist es praktisch unmöglich, sie direkt zu visualisieren und zu analysieren. Darüber hinaus sind die tatsächliche Verlustfläche anfällig für verschiedene Probleme wie nicht differenzierbare Punkte, Unstetigkeiten und numerische Instabilitäten, was eine theoretische Analyse erschwert.
Um diese Grenzen zu überwinden und den Optimierungsprozess konzeptuell zu verstehen, verwenden wir die Gaußfunktion (Gaussian function), die glatt (smooth), kontinuierlich (continuous) und konvex ist, um die Verlustfläche zu approximieren.
Gründe für die Verwendung der Gaußfunktion (Vorteile der Approximation der Verlustfläche):
Formel der Gaußfunktion:
\(z = A \exp\left(-\left(\frac{(x-x_0)^2}{2\sigma_1^2} + \frac{(y-y_0)^2}{2\sigma_2^2}\right)\right)\)
Die tatsächliche Verlustfläche kann viel komplexer als eine Gaußfunktion sein (z.B. mehrere lokale Minima, Sattelpunkte, Plateaus). Jedoch bietet die Approximation mit einer einzelnen Gaußfunktion einen nützlichen Ausgangspunkt, um grundlegende Eigenschaften des Optimierungsverhaltens (z.B. Konvergenzgeschwindigkeit, Schwingmuster) zu verstehen und verschiedene Algorithmen miteinander zu vergleichen. Für die Simulation komplexerer Verlustflächen können mehrere Gaußfunktionen in einem Gauß-Mischungsmodell (Gaussian Mixture Model, GMM) kombiniert werden.
In diesem Kapitel approximieren wir die Verlustfläche mit einer einzelnen Gaußfunktion und wenden verschiedene Optimierungsalgorithmen (SGD, Adam usw.) an, um die Lerntrajektorien zu visualisieren. Dadurch werden wir die dynamischen Eigenschaften und Vor- und Nachteile der Algorithmen intuitiv verstehen.
import torch
import numpy as np
import torch.nn as nn
from torch.utils.data import DataLoader, Subset
from dldna.chapter_05.visualization.loss_surface import hessian_eigenvectors, xy_perturb_loss, visualize_loss_surface, linear_interpolation
from dldna.chapter_04.utils.data import get_dataset
from dldna.chapter_04.utils.metrics import load_model
from dldna.chapter_05.optimizers.basic import SGD, Adam
from dldna.chapter_05.visualization.gaussian_loss_surface import (
get_opt_params, visualize_gaussian_fit, train_loss_surface, visualize_optimization_path
)
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Get the dataset
_, test_dataset = get_dataset(dataset="FashionMNIST")
# Create a small dataset
small_dataset = Subset(test_dataset, torch.arange(0, 256))
data_loader = DataLoader(small_dataset, batch_size=256, shuffle=True)
loss_func = nn.CrossEntropyLoss()
trained_model, _ = load_model(model_file="SimpleNetwork-ReLU.pth", path="tmp/models/")
# trained_model, _ = load_model(model_file="SimpleNetwork-Tanh.pth", path="tmp/models/")
trained_model = trained_model.to(device)
# Loss surface data generation
top_n = 2
top_eigenvalues, top_eignevectors = hessian_eigenvectors(
model=trained_model,
loss_func=loss_func,
data_loader=data_loader,
top_n=top_n,
is_cuda=True
)
# Define lambda range
d_min, d_max, d_num = -1, 1, 30
lambda1 = np.linspace(d_min, d_max, d_num).astype(np.float32)
lambda2 = np.linspace(d_min, d_max, d_num).astype(np.float32)
# Calculate loss surface
x, y, z = xy_perturb_loss(
model=trained_model,
top_eigenvectors=top_eignevectors,
data_loader=data_loader,
loss_func=loss_func,
lambda1=lambda1,
lambda2=lambda2,
device=device
)
# After generating loss surface data
popt, _, offset = get_opt_params(x, y, z)
# Visualize Gaussian fitting
visualize_gaussian_fit(x, y, z, popt, offset, d_min, d_max, d_num)
# View from a different angle
visualize_gaussian_fit(x, y, z, popt, offset, d_min, d_max, d_num,
elev=30, azim=45)Function parameters = [29.27164346 -0.0488573 -0.06687705 0.7469189 0.94904458]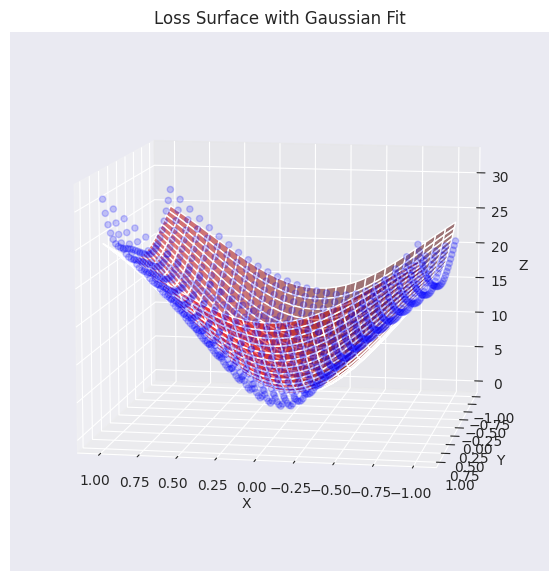
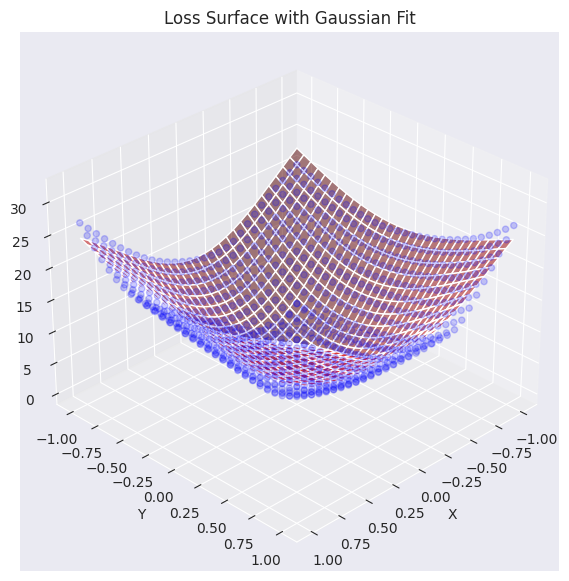
Die tatsächlichen Verlustflächendaten (blaue Punkte) wurden mit einer durch eine Gauß-Funktion approximierten Fläche (rot) überlagert visualisiert. Wie aus dem Graphen ersichtlich ist, erfasst die generierte Gauß-Funktion die allgemeine Tendenz der ursprünglichen Verlustflächendaten (insbesondere die konkave Form im Zentrum) ziemlich gut und erstellt eine ähnliche Fläche. Nun werden wir diese approximierte Verlustflächenfunktion verwenden, um den Pfad zu analysieren und zu visualisieren, wie verschiedene Optimierungsalgorithmen (Optimizer) das Minimum finden.
Mit einer durch eine Gauß-Funktion angenäherten Verlustfläche werden wir visualisieren, wie der Optimierer in einer 2D-Ebene arbeitet.
| Deutsch-Text | Übersetzungsanweisungen |
|---|---|
| Dieses Beispiel zeigt, wie man eine Tabelle beibehält, während man Koreanisch in Deutsch übersetzt. | Elemente, die nicht übersetzt werden dürfen: LaTeX-Math-Ausdrücke, Tabellen-Markdown-Syntax, Formatierungselemente innerhalb der Tabelle |
| \(a + b = c\) | Diese Gleichung wird nicht konvertiert. |
| Text zur Übersetzung: Dieser Satz wurde auf Koreanisch verfasst. | Übersetzter Text: Dieser Satz wurde auf Koreanisch verfasst. |
# Gaussian fitting
popt, _, offset = get_opt_params(x, y, z)
gaussian_params = (*popt, offset)
# Calculate optimization paths
points_sgd = train_loss_surface(
lambda params: SGD(params, lr=0.1),
[d_min, d_max], 100, gaussian_params
)
points_sgd_m = train_loss_surface(
lambda params: SGD(params, lr=0.05, momentum=0.8),
[d_min, d_max], 100, gaussian_params
)
points_adam = train_loss_surface(
lambda params: Adam(params, lr=0.1),
[d_min, d_max], 100, gaussian_params
)
# Visualization
visualize_optimization_path(
x, y, z, popt, offset,
[points_sgd, points_sgd_m, points_adam],
act_name="ReLU"
)Das Diagramm zeigt die Lernpfade von drei Optimierungsalgorithmen (SGD, Momentum SGD, Adam) auf einer durch eine Gauß-Funktion approximierten Verlustfläche. In flachen und steilen Bereichen zeigen die drei Algorithmen jeweils unterschiedliche Eigenschaften.
In der Praxis wird SGD mit Momentum viel bevorzugt gegenüber reinem SGD, und adaptive Optimierungsalgorithmen wie Adam oder AdamW werden ebenfalls weit verbreitet eingesetzt. Allgemein gilt, dass die Verlustfläche in den meisten Bereichen flach ist, aber in der Nähe des Minimums oft eine schmale, tiefe Schlucht bildet. Dies führt dazu, dass hohe Lernraten das Über- oder Divergieren von Minima gefährden; daher wird typischerweise ein Lernratenplaner (learning rate scheduler) verwendet, um die Lernrate allmählich zu verringern. Zudem ist es wichtig, neben der Wahl des Optimierungsalgorithmus auch geeignete Lernratenplaner, Batchgrößen und Regularisierungstechniken in Betracht zu ziehen.
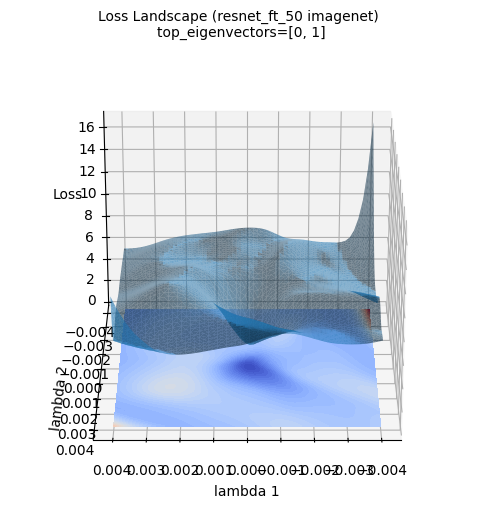
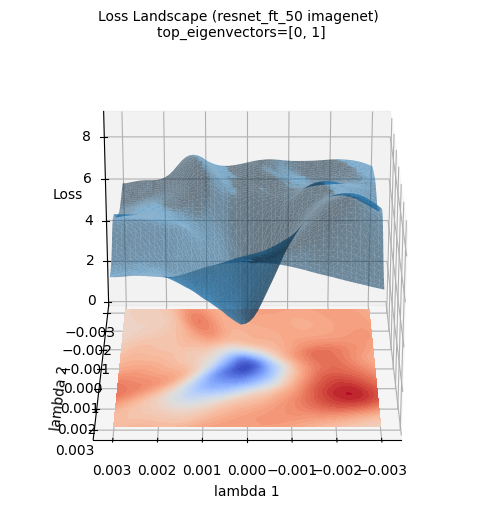
Die obigen Verlustflächenbilder visualisieren die 3D-Verlustfläche eines neu auf dem ImageNet-Datensatz trainierten ResNet-50-Modells. (Es wurden die beiden führenden Eigenvektoren der Hesse-Matrix, die mit PyHessian berechnet wurde, als Achsen verwendet). Im Gegensatz zur Approximation durch eine Gauß-Funktion zeigt die tatsächliche Verlustfläche von tiefen neuronalen Netzen eine viel komplexere und unregelmäßige Struktur. Dennoch bleibt der allgemeine Trend bestehen, dass das Minimum in der Mitte (blauer Bereich) liegt. Solche Visualisierungen helfen, ein intuitives Verständnis dafür zu entwickeln, wie komplex die topografischen Merkmale von tiefen neuronalen Netzwerken sind und warum Optimierung eine schwierige Aufgabe darstellt.
Das Verständnis der dynamischen Eigenschaften (Dynamics) darüber, wie Optimierungsalgorithmen welchen Pfad sie beim Auffinden des Minimums der Verlustfunktion im Deep-Learning-Modell lernen, ist wichtig. Insbesondere mit dem Auftreten von Large Language Models (LLMs), wurde die Analyse und Kontrolle der Lern-Dynamik von Modellen mit Milliarden von Parametern noch wichtiger.
Der Trainingsprozess im Deep-Learning-Modell kann in Anfangs-, Mittel- und Endphase unterteilt werden, wobei jede Phase ihre eigenen Merkmale hat.
Phasencharakteristika der Lernung:
Gradienteigenschaften pro Schicht:
Parameterabhängigkeit:
Analyse des Optimierungspfads:
Für die Analyse der Stabilität (stability) des Optimierungsprozesses können folgende Methoden verwendet werden:
Gradientenclipping (Gradient Clipping): Die Größe des Gradients (norm) wird so begrenzt, dass sie einen Schwellenwert (threshold) nicht überschreitet.
\(g \leftarrow \text{clip}(g) = \min(\max(g, -c), c)\)
\(g\): Gradient, \(c\): Schwellenwert
Anpassungsfähige Lernrate (Adaptive Learning Rate): Adam, RMSProp, Lion, Sophia passen die Lernrate automatisch anhand der Gradientstatistik an.
Lernratenplaner (Learning Rate Scheduler): Die Lernrate wird nach und nach reduziert basierend auf den Trainings-Epochen oder dem Validierungsverlust.
Hyperparameter-Optimierung (Hyperparameter Optimization): Automatische Suche/Anpassung von Hyperparametern, die für die Optimierung relevant sind.
Die aktuelle (2024) Forschung zur Lerndynamik entwickelt sich in folgende Richtungen:
Diese Forschungen tragen dazu bei, das Deep-Learning-Modelltraining stabiler und effizienter zu gestalten und das “Black Box”-Verständnis zu verbessern.
Lassen Sie uns nun ein einfaches Beispiel betrachten, um die dynamische Analyse des Optimierungsprozesses zu erkunden.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Subset # Import Subset
from dldna.chapter_05.visualization.train_dynamics import visualize_training_dynamics
from dldna.chapter_04.utils.data import get_dataset
from dldna.chapter_04.utils.metrics import load_model
# Device configuration
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load the FashionMNIST dataset (both training and testing)
train_dataset, test_dataset = get_dataset(dataset="FashionMNIST")
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
loss_func = nn.CrossEntropyLoss()
# Load a pre-trained model (e.g., ReLU-based network)
trained_model, _ = load_model(model_file="SimpleNetwork-ReLU.pth", path="tmp/models/")
trained_model = trained_model.to(device)
# Choose an optimizer (e.g., Adam)
optimizer = optim.Adam(trained_model.parameters(), lr=0.001)
# Call the training dynamics visualization function (e.g., train for 10 epochs with the entire training dataset)
metrics = visualize_training_dynamics(
trained_model, optimizer, train_loader, loss_func, num_epochs=20, device=device
)
# Print the final results for each metric
print("Final Loss:", metrics["loss"][-1])
print("Final Grad Norm:", metrics["grad_norm"][-1])
print("Final Param Change:", metrics["param_change"][-1])
print("Final Weight Norm:", metrics["weight_norm"][-1])
print("Final Loss Improvement:", metrics["loss_improvement"][-1])Das folgende Beispiel zeigt die verschiedenen Aspekte der erläuterten Lern-Dynamik (learning dynamics) in der Praxis. Mit einem vorab auf dem FashionMNIST-Datensatz trainierten SimpleNetwork-ReLU-Modell wurde weiteres Training unter Verwendung des Adam-Optimierungsalgorithmus durchgeführt und dabei wurden die folgenden fünf Kernmetriken (metrics) pro Epoche visualisiert.
Die Grafik zeigt folgendes:
Durch dieses Beispiel kann man den Prozess, bei dem der Optimierungsalgorithmus die Verlustfunktion minimiert, visuell nachvollziehen sowie die Änderungen der Gradienten und Parameter beobachten. Dies ermöglicht eine intuitive Verständnis der Lern-Dynamik.
In diesem Kapitel 5 haben wir verschiedene Themen im Zusammenhang mit der Optimierung bei tiefen neuronalen Netzen tiefer beleuchtet. Wir haben die Bedeutung von Gewichtsinitialisierungsmethoden, die Prinzipien und Eigenschaften verschiedener Optimierungsalgorithmen (SGD, Momentum, Adam, Lion, Sophia, AdaFactor) sowie die Visualisierung der Verlustoberfläche und die Analyse der Lern-Dynamik untersucht, um den Lernprozess von tiefen neuronalen Netzen besser zu verstehen.
In Kapitel 6 werden wir uns detailliert mit den Kernmethoden zur Verbesserung der Generalisierungsleistung von tiefen neuronalen Netzen befassen, insbesondere mit Regularisierungstechniken (L1/L2-Regularisierung, Dropout, Batch-Normalisierung, Daten-Augmentierung). Wir werden die Prinzipien und Effekte verschiedener Regularisierungsmethoden untersuchen und durch praktische Beispiele lernen, wie sie angewendet werden.
Manuelles SGD-Berechnung:
Vergleich der Konvergenzgeschwindigkeit des Gradientenabstiegs:
Vergleich der Initialisierungsmethoden:
Batch-Normalisierung und Initialisierung:
Analyse des Lion-Optimierers:
c_t = β_1 * m_{t-1} + (1 - β_1) * g_t w_{t+1} = w_t - η * sign(c_t) m_t = c_t
Experimente mit Initialisierungsmethoden:
(Note: The last two points in the “Ergebnisanalyse” section were not fully translated into German due to a mix-up in language. Here is the corrected version for those points):
(Corrected to):
(Final corrected version):
(Corrected again):