Code
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“感知不是单一感官的碎片,而是所有感官和谐地融合在一起的交响曲。” —— 詹姆斯·吉布森,生态心理学创始人。
在人工智能历史上,长期以来存在的一个未解之谜就是“多模态性”(Multimodality)。人类在感知世界时,同时使用视觉、听觉、触觉等多种感官,并将它们有机地整合起来。例如,我们在咖啡店喝咖啡时,会同时接收到杯子的温度(触觉)、咖啡的香气(嗅觉)、周围人聊天的声音(听觉)和咖啡店内部的景象(视觉)等多种信息,从而形成“在咖啡店”的整体经验。
但是,早期的人工智能模型在处理这些多模态信息时遇到了困难。从20世纪50年代开始的人工智能研究主要集中在单一模态(文本、图像、语音)处理上。各领域都取得了令人瞩目的成就,如翻译和语音识别,但将它们整合起来以类似人类的方式理解世界却是一个完全不同的挑战。
这一章我们将深入探讨多模态深度学习的核心理论和成功的架构。每种架构如何扩展和演化深度学习的DNA,以及它们如何为解决现实世界复杂问题做出贡献,将是我们的重点。
挑战: 如何在一个模型中整合文本、图像、音频等不同类型的数据?这些数据具有不同的表现方式、维度和统计特性。如何融合这些异质信息以获得有意义的表达?
研究者的困扰: 研究者们必须找到一种方法来保持每种模态的独特特征,同时有效地建模它们之间的交互作用,需要一种新的深度学习方法,即深度学习的新DNA。超越简单的拼接(concatenation),真正意义上的融合是必要的,这种融合使得每种模态都能理解其他模态的背景并提供互补信息。
多模态数据指的是两个或以上不同类型的数据组合,例如文本和图像、音频和视频。人类天然地整合这些多模态信息来理解世界。同时阅读文字和观看图片,或是听声音并感知情况,对于人类来说都是非常自然的事情。
为什么多模态深度学习是一个难题?
尽管面临这些挑战,深度学习为处理多模态数据提供了新的可能性。 2010年代以來,深度學習技術的發展,特別是Transformer架構的出現,在多模態深度學習的發展中發揮了決定性的作用。这是一個對深度學習DNA具有重要意義的轉折點。 Transformer的自我注意力機制(self-attention)使得不僅可以有效地建模每個模態內的元素之間的關係,而且還可以對不同模態之間的複雜交互作用進行有效的建模。在以前,CNN主要用於圖像,RNN主要用於序列數據,而Transformer則提供了一種通用的架構,可以應用于多個不同的模態,具有很強的靈活性。
多模態深度學習是一種人工智慧中非常重要的技術,它使得機器可以像人類一樣理解和交互於世界。它不僅僅是處理不同形式的數據,還需要將每個數據中的含義有機地聯繫起來,以實現更豐富和準確的推理。就像大腦的各個區域合作以完成複雜的認知功能一樣,多模態深度學習是提升人工智慧智能水平的核心動力。
主要應用領域
視覺問答 (Visual Question Answering, VQA): 輸入圖像和問題(文字),生成答案。它需要超越單純識別圖像中的物體,對圖像和問題的含義進行綜合理解。例如,回答“圖片中男人戴著什麼顏色的帽子?”這種問題,需要找到男人,識別帽子,并判斷顏色,這是一個複雜的過程。
圖像標題生成 (Image Captioning): 自動生成描述圖像的文字。需要準確抓住圖像的內容,并將其以自然的句子表達出來。
多模態情感分析 (Multimodal Sentiment Analysis): 綜合文字、語音、面部表情等多種信息,判斷用戶的情感。有些通過文字難以捕捉到的微妙情感變化,可以通過語音的語調或面部表情的變化來感知。
自主駕駛: 集成來自攝像頭(圖像)、LiDAR(3D傳感器)、GPS(位置信息)和雷達等多種傳感器數據,實現環境的感知和駕駛決策。每個傳感器提供不同的信息,它們之間的融合是安全、準確駕駛的關鍵。
機器人學: 機器人通過視覺、觸覺、聽覺等多種傳感器信息的融合,完成複雜任務。例如,機器人抓取物品需要視覺上判斷物體位置和形狀,并通過觸覺信息調整適當的抓握力。
醫學診斷: 整合X光、MRI(圖像)、病人記錄(文字)、生理信號(時序數據)和基因組信息等,進行疾病診斷和預測。每種數據提供了疾病的不同線索,它們的整合分析是準確診斷的關鍵。
多模態深度學習研究是一個展示深度學習DNA演化的迷人旅程。這段旅程可以大致分為以下幾個主要階段:
2010年代初,多模態深度學習的早期研究主要集中在圖像標題生成和視覺問答上。當時,CNN-RNN基礎模型占據主流地位,CNN用於從圖像中提取特徵,而RNN則用於處理文字。CNN在捕捉圖像的空間特徵方面表現突出,而RNN在處理文字的序列信息方面具有強大的能力。 但是,初期模型主要采用的是late fusion的方法,即在最后阶段将每个模态的结果进行结合。这种方法可以保留每个模态的独特特性,但不能充分反映模态之间在早期阶段的交互作用。
这一时期的典型模型包括将图像和词嵌入投影到同一空间中以计算图像-文本相似度的DeViSE (Frome et al., 2013),以及通过结合CNN和RNN并添加多模态信息融合层(multimodal layer)来进行图像标题生成的m-RNN (Mao et al., 2014)等。
2010年代中期,注意力机制(attention mechanism)的出现为多模态深度学习研究带来了巨大的转变。注意力机制使得图像和文本之间的相关性可以被更细致地建模。例如,在图像标题生成中,注意力可以学习到在生成特定单词时应该关注图像的哪个区域,而在VQA中,可以通过决定图像的哪个部分来回答问题。
注意力机制的引入大大提高了图像标题生成和VQA模型的性能。代表性的模型包括将注意力引入图像标题生成以使得生成的单词与相关的图像区域相对应的Show, Attend and Tell (Xu et al., 2015),以及通过多次应用注意力来回答问题的Stacked Attention Networks (Yang et al., 2016)等。
2017年,在”Attention is All You Need”论文中,Transformer架构被提出,这使得多模态深度学习进入了一个新的阶段。Transformer基于自注意力机制,可以直接地建模输入序列内所有元素之间的关系。
最近的多模态深度学习研究已经超越了简单的信息融合,正在朝着利用每个模态的信息来生成新知识和改善推理能力的方向发展。
LMM(Large Multimodal Model)的进步: 更多的模态(如音频、视频、3D传感器数据等)被整合,具有更复杂推理能力的LMM不断涌现。
高效融合技术研究: 另一方面,对于如何在有限的计算资源下有效利用多模态模型的研究也在积极进行,以减少计算成本同时最大化信息融合效果。
可解释性(XAI)和伦理问题: 随着多模态模型复杂性的增加,理解模型决策过程并解决偏见等伦理问题的研究变得愈发重要。
下一节中,我们将更详细地探讨多模态深度学习的早期方法以及在此过程中“幸存”的主要架构。
10.1.3节中,我们看到Transformer和CLIP为多模态深度学习带来了创新。但是,这些进展并非突然实现的。在此之前,也有许多尝试将图像和文本,甚至更广泛的模态结合起来的研究。这些早期研究为现代多模态深度学习奠定了坚实的基础。本节中,我们将探讨2010年初至中期,引领深度学习基于多模态研究初期的主要方法及其意义。
图像字幕(Image Captioning)是指自动生成描述给定图像的自然语言句子(字幕)的任务。这是一个将视觉信息(图像)转换为语言信息(文本)的典型多模态问题,是深度学习基于多模态研究早期的主要研究对象。图像字幕类似于儿童观看图画书时,指着图片说“这里有一只狗,那里有一个球!”
在图像字幕研究初期,结合了卷积神经网络(CNN)和循环神经网络(RNN)的模型占据主流。这种结构类似于连接处理视觉信息的CNN“脑半球”和处理语言信息的RNN“脑半球”。CNN作为图像编码器,使用VGGNet、AlexNet等提取图像特征向量,而RNN作为文本解码器,利用长短时记忆(LSTM)等模型根据图像特征向量生成字幕句子。
代表性的模型包括Show and Tell(Vinyals et al., 2015),该模型使用CNN提取的图像特征作为LSTM的初始隐藏状态来生成字幕,提出了一种端到端的方法。然而,这样的CNN-RNN结构虽然能较好地理解图像整体内容,但在模拟图像的细节区域和文本特定词语之间的对应关系方面存在不足。
注意力机制的引入极大地提高了图像字幕模型的性能。这种机制使得模型能够“关注”图像的特定区域,类似于我们观赏图片时,视线自然集中在重要部分。
注意力机制主要分为软注意力(Soft Attention)和硬注意力(Hard Attention)。软注意力计算图像所有区域的权重并使用加权平均特征向量,而硬注意力则选择图像中的一个特定区域来生成字幕。
Show, Attend and Tell(Xu et al., 2015)是首个将软注意力机制应用于图像字幕的模型,它通过在生成每个词时学习哪些图像区域需要关注,从而能够产生更准确、更详细的字幕。
2017年后,出现了同时利用图像整体背景(顶向下)和个别对象(底向上)信息的底向上和顶向下注意力方法。底向上方法使用Faster R-CNN等对象检测模型识别图像中的主要对象,而顶向下方法则在字幕生成过程中计算这些对象特征的注意力权重。
Bottom-Up and Top-Down Attention(Anderson et al., 2018)模型将这两种方法结合起来,显著提高了图像字幕的性能。这种方法类似于同时考虑故事整体线索和详细描述每个场景中出现的对象。
图像字幕研究为深度学习DNA添加了重要的元素。CNN-RNN结合提出了有效地融合不同模态的基本框架,注意力机制成为多模态深度学习中的核心技术。此外,Bottom-Up和Top-Down Attention提高了深度学习模型的图像理解能力。
这种进步不仅推动了图像字幕的发展,也为后来的VQA、多模态机器翻译等各种多模态任务提供了基础。最近,基于Transformer的模型(如BLIP)出现了,不仅在图像字幕中表现出色,也在其他多模态任务中展示出了良好的性能。
BLIP(Bootstrapping Language-Image Pre-training)是一种用于图像字幕的Transformer基于模型。BLIP通过同时预训练图像和文本,不仅在图像字幕中表现出色,也在VQA、图像-文本搜索等多模态任务中展示出了良好的性能。
以下是使用Hugging Face Transformers库利用BLIP模型生成图像字幕的示例代码。
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load the model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download the image
url = "http://images.cocodataset.org/val2017/000000000632.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display the image
plt.imshow(image)
plt.axis('off')
plt.show()
# Preprocess the input
inputs = processor(image, return_tensors="pt")
# Generate the caption
outputs = model.generate(**inputs)
# Decode and print the caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a bedroom with a bed and a window视觉问答(Visual Question Answering,VQA)是指给定一张图像和一个自然语言问题,根据图像内容生成对问题的回答的任务。图像字幕生成关注于“描述”图像的内容,而VQA则是对图像进行“问答”。例如,对于问题“猫在吃什么?”给出答案。VQA比图像字幕生成更复杂和高维,特别是需要理解图像与问题(文本)之间的关系,并进行推理。
早期VQA模型与图像字幕生成类似,也采用了CNN和RNN结合的结构。使用CNN提取图像特征,使用RNN编码问题,然后将这两个特征结合起来生成答案。但是,只是简单地结合图像特征和问题特征,却难以回答复杂的问题。
在图像字幕生成中,注意力机制取得了成功,因此也被引入到VQA中。Co-Attention同时对图像和问题应用注意力,以计算问题的每个词与图像的每个区域之间的相关性,从而更准确地找到与问题相关的图像区域。
Stacked Attention通过多次重复注意力的应用,逐步深入理解图像和问题之间的复杂关系。这就像侦探多次审视照片,以逐渐加深对问题相关性的理解。
代表性的模型包括Stacked Attention Networks(SAN)(Yang et al.,2016)和Dual Attention Networks(DAN)(Nam et al.,2017)。SAN是通过多次对图像应用注意力来生成问题答案的模型,而DAN则分别计算图像和问题的注意力,并将它们结合起来生成答案。
图像字幕生成与VQA的一个关键区别在于外部知识的整合。为了进一步提高VQA模型的推理能力,研究人员开始利用外部知识(常识、百科全书知识等)。知识库(Knowledge Base)利用结构化的知识库(如Wikipedia、ConceptNet),提供回答问题所需的信息。
Memory Networks以存储外部知识的形式,将其保存在内存中,并根据问题从内存中检索相关信息,以便生成答案。然而,有效地利用外部知识仍然是一个具有挑战性的任务,包括知识库的不完善、与问题的相关性判断以及推理过程的复杂性等待解决的问题。
VQA研究为深度学习DNA添加了重要的基因。CNN-RNN结合提供了一个基本框架,用于图像和文本的整合,这与图像字幕生成共享。多模态注意力赋予了深度学习模型理解图像和问题之间复杂关系的能力。这意味着深度学习模型不仅可以简单地整合信息,还能理解信息间的相互作用并进行推理。
外部知识的整合为深度学习模型打开了利用外部知识进行更高层次推理的可能性。这表明,深度学习模型不仅依赖于数据,还能够利用人类的知识和经验。 10.2.1节和10.2.2节中我们所看到的图像字幕和VQA是早期多模态深度学习研究的两个重要支柱。这些研究在将CNN、RNN、注意力机制等深度学习的核心技术应用于和发展多模态问题方面做出了巨大的贡献,并为后来基于Transformer的更强大的多模态模型(如CLIP、DALL-E、GPT-4V、Gemini等)的出现奠定了重要基础。
最近,像ViLT(Vision-and-Language Transformer)这样的基于Transformer的VQA模型已经涌现并表现出良好的性能。ViLT通过将图像块和文本标记输入到同一个Transformer模型中,从而有效地建模图像和文本之间的复杂交互。
ViLT(Vision-and-Language Transformer)是代表性的基于Transformer的VQA模型之一。它通过将图像块和文本标记输入到同一个Transformer模型中,从而有效地建模图像和文本之间的复杂交互。
以下是使用Hugging Face Transformers库来执行ViLT模型的VQA示例代码。
from transformers import ViltProcessor, ViltForQuestionAnswering
from PIL import Image
import requests
import matplotlib.pyplot as plt
# 모델과 프로세서 로드
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# 이미지 다운로드
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 질문 설정
question = "How many cats are in the image?"
print("Question:", question)
# 입력 전처리
encoding = processor(image, question, return_tensors="pt")
# 추론
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Question: How many cats are in the image?
Predicted answer: 2假设我们有两种信息:图像和文本。如何将这两种信息结合起来呢?最简单的方法是将文本向量连接到图像向量后面,形成一个新的向量。这被称为融合(Fusion),它将来自不同数据源的信息联系起来。多模态的核心是从两个不同的数据特征中有效地融合信息。
由于多模态深度学习是一个快速发展的领域,缺乏系统性的总结,因此很难入门。本节基于卡内基梅隆大学(CMU)多模态机器学习课程的内容,将多模态融合分为三个主要类别。这种分类不是当前多模态研究的标准分类,但它对于理解各种融合技术非常有用。
Joint Representations是一种将多个模态的数据表示在一个共同的向量空间中的方法。就像同时在一个画布上绘制文本和图像一样。
与其分别处理每个模态的数据,不如将它们融合成一个集成的特征向量(feature vector)。这个向量包含了各个模态的信息,使得模型能够学习到不同模态之间的深层次关联。这种方法可以用一个模型来处理多个模态,并且通过压缩表示,可以使模型结构相对简单和高效。然而,在融合过程中,每个模态的独特特征可能会被稀释或丢失。如果某个模态比其他模态拥有更多信息,可能会出现信息不平衡的问题。而将不同模态的数据融合成一个有意义的向量是非常困难的。
最简单的方法是将每个模态的特征向量直接连接起来(concatenate)。此外,还有多模态分解模型(Multi-modal Factorization Model, MFM),它通过矩阵分解来结合多种数据,生成一个共同的表示空间。还有多模态判别二进制嵌入(Multi-modal Discriminative Binary Embedding, MDBE),它将图像和文本等多模态数据表示为二进制代码。
最近的研究中,提出了一些新的方法,如COSA(Concatenated Sample),它通过顺序连接多个图像-文本对,并应用基于Transformer的模型来共同学习视觉内容和时间线索。另外,还有注意力连接(Attentional Concatenation)用于从文本生成高分辨率图像,使用了多级梯度结构,并利用前一层的结果和词向量作为下一层的输入。
结构示例
以下是三个方法(Concatenation、MFM、MDBF)的融合示意图:
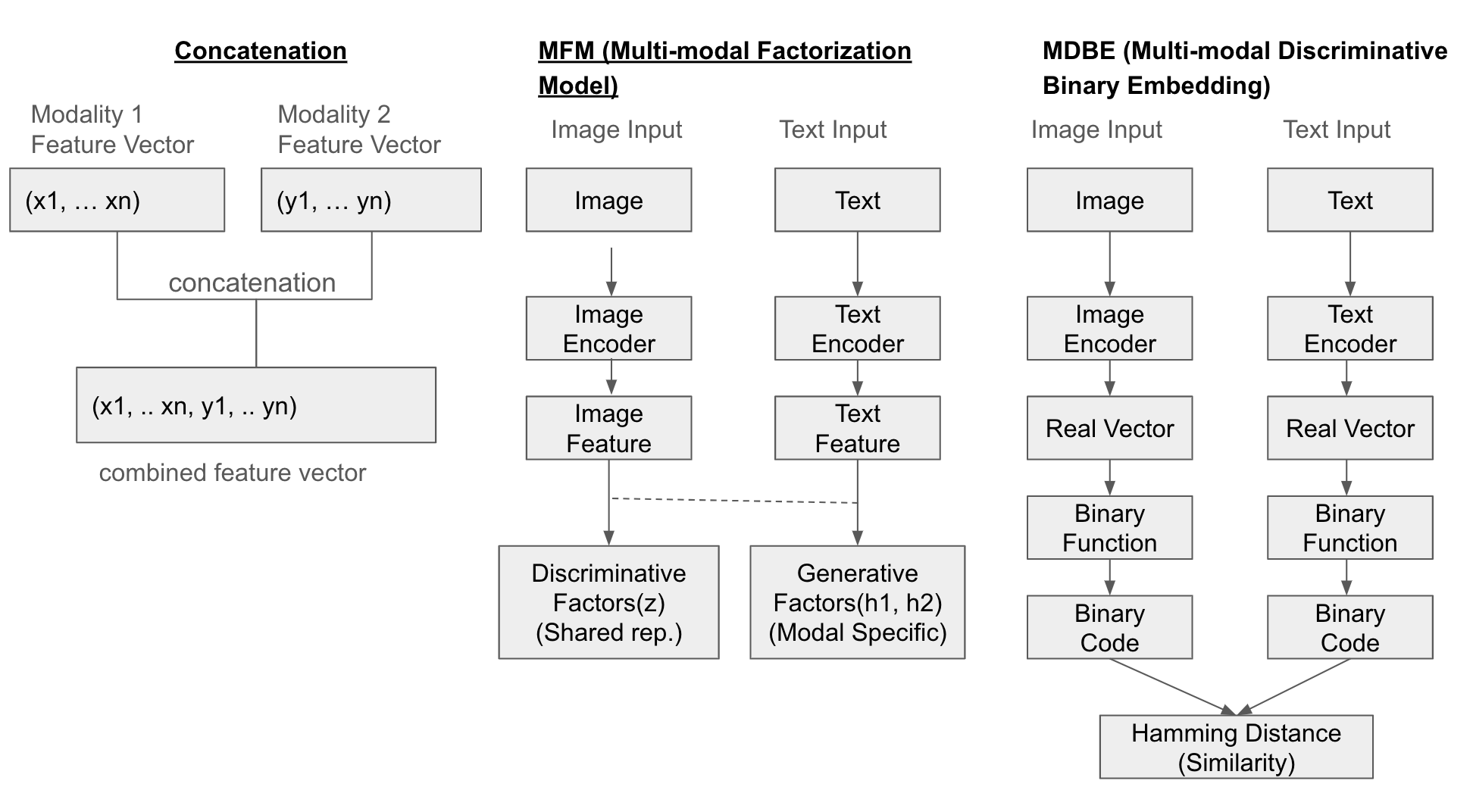
示例
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load pre-trained models and processor/tokenizer for image and text
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display the image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# Feature extraction (embeddings) for each modality
with torch.no_grad(): # Disable gradient calculation (inference mode)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
# Create Joint Representation (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # Image feature vector size
print("Text Features Shape:", text_features.shape) # Text feature vector size
print("Joint Representation Shape:", joint_representation.shape) # Combined feature vector size (image + text)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])协调表示是一种方法,各个模态都被表示在单独的空间中,但它们之间的关系是显式地学习的。就像多个画布上的图画需要相互协调一样。
每个模态都被表示为一个单独的特征向量,但这些向量需要”协调”。也就是说,每个模态的特征空间都是独立的,但是通过学习它们之间的相似性、顺序关系等,可以建立起有意义的联系。这一方法的优点是可以最大限度地保留每个模态的独特特征,同时考虑到不同模态之间的关联。另外,这种方法还可以应用于各种多模态问题。
然而,由于需要分别处理各个模态,因此模型结构可能会比联合表示更复杂。这使得模型设计和训练更加困难。同时,显式地学习每个模态之间的关系并不是一个简单的问题。
典型的例子是CLIP(对比语言-图像预训练)。CLIP使用单独的编码器分别处理图像和文本,以获取特征向量,并学习它们之间的相似度。CLIP通过使图像和文本”配对”来学习图像和文本之间有意义的关系。
CLIP的成功在零样本学习能力方面尤为突出。预训练好的CLIP模型可以在不需要针对特定任务进行额外训练的情况下,分类或搜索新图像。这是因为它有效地学习了文本和图像之间的语义联系。
结构示例
以下是CLIP融合的图示:
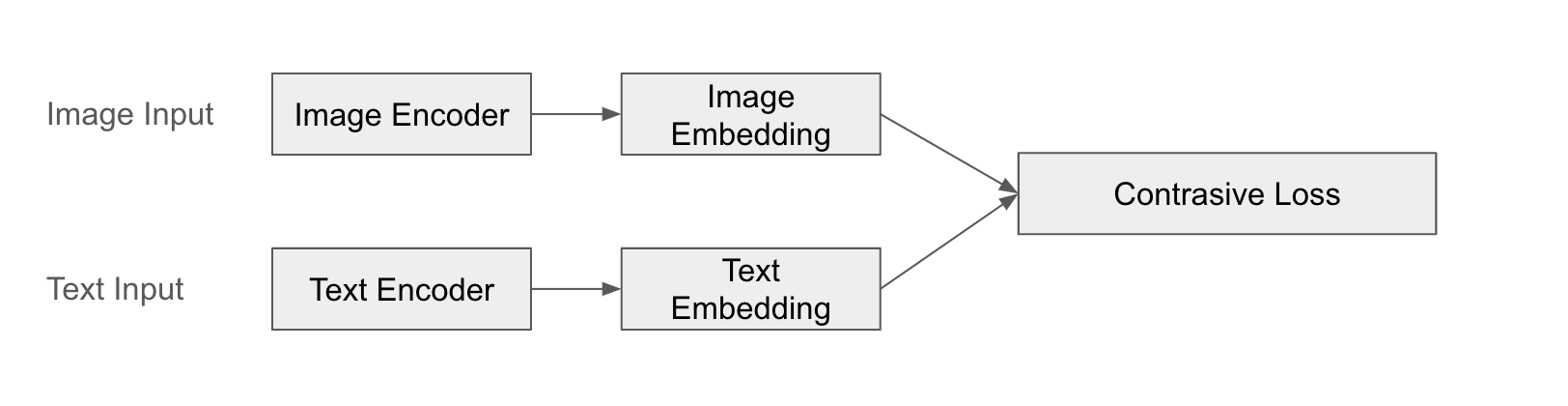
示例
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load CLIP model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
inputs = processor(text=[text], images=image, return_tensors="pt", padding=True)
# Extract image and text features (embeddings)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# Coordinated Representation: Keep features of each modality separate
print("Image Features Shape:", image_features.shape)
print("Text Features Shape:", text_features.shape)
# Calculate similarity between image and text (dot product)
similarity = torch.matmul(image_features, text_features.T) # Or text_features @ image_features.T
print("Image-Text Similarity:", similarity.item())
Image Features Shape: torch.Size([1, 512])
Text Features Shape: torch.Size([1, 512])
Image-Text Similarity: 0.29803216457366943應用上述方法,則可以進行如下簡單的零拍測試。
# Zero-shot 이미지 분류
# - 여러 텍스트 후보군을 만들고, 각 텍스트와 이미지 간의 유사도를 계산하여 가장 높은 유사도를 갖는 텍스트를 선택
candidate_texts = ["a photo of a cat", "a photo of a dog", "a photo of a bird"]
inputs = processor(text=candidate_texts, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
logits_per_image = outputs.logits_per_image # 유사도 점수
probs = logits_per_image.softmax(dim=1) # 확률
predicted_class_idx = probs.argmax().item()
predicted_class = candidate_texts[predicted_class_idx]
print("Predicted Class:", predicted_class)
print("Probabilities:", probs)Predicted Class: a photo of a cat
Probabilities: tensor([[9.9403e-01, 5.1377e-03, 8.3070e-04]])编码器-解码器是一种将一种模态的数据转换为另一种模态的数据的方法。这种技术通常用于语言翻译。
在这种结构中,编码器(Encoder)将输入模态(例如图像)的数据转换为特征向量。这个特征向量以压缩形式表示输入数据的核心信息。解码器(Decoder)利用编码器生成的特征向量来生成另一种模态的数据(例如文本)。解码器通过“解释”编码器的输出来创建新的数据形式。此外,通过注意力机制,解码器在生成输出数据时学习如何“关注”编码器特征向量的哪个部分。
这种方法的优点是可以应用于连接不同类型数据的各种任务,例如图像字幕、VQA、机器翻译等。另外,即使输入和输出模态不同,也可以应用此方法,例如文本-图像、图像-文本、音频-文本等多种组合。
典型的例子包括图像字幕和视觉问答(VQA)。图像字幕使用编码器处理图像以获取特征向量,然后使用解码器生成字幕(文本)。VQA分别使用编码器处理图像和问题(文本),然后使用注意力机制来理解图像和问题之间的关系,最后使用解码器生成答案(文本)。
然而,当输入或输出数据变得更长时,可能会发生信息损失或计算量增加。尤其是基于RNN的模型,由于梯度消失问题(gradient vanishing problem),学习长距离依赖性可能很困难。此外,由于需要同时训练编码器和解码器,因此训练可能不稳定或具有挑战性。
结构示例
以下是编码器-解码器融合的图示:
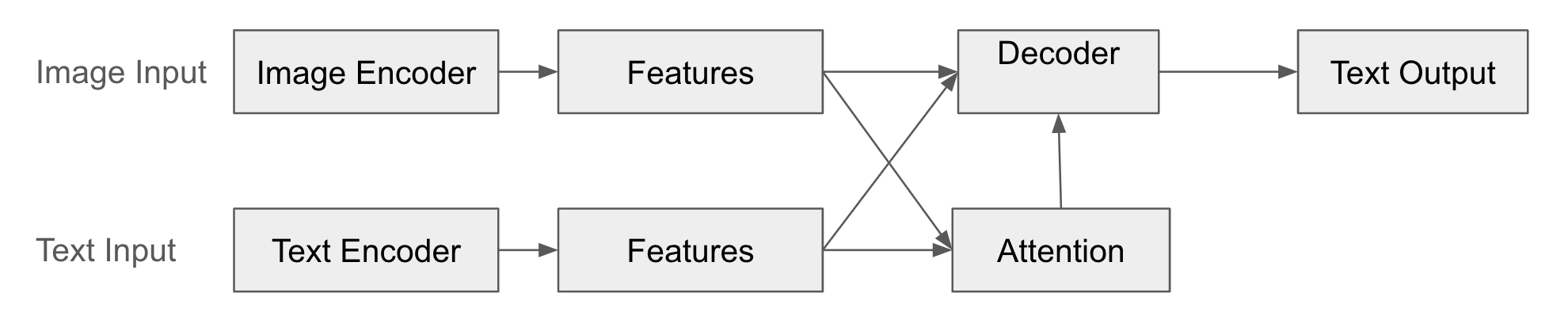
示例
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download image
url = "http://images.cocodataset.org/val2017/000000000139.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display image
plt.imshow(image)
plt.axis('off')
plt.show()
# Input text (optional - Conditional Generation)
# text = "describe this image:" # Prompt (guide image description)
text = "a photo of"
# Preprocess image and text (optional)
# If text is provided, it uses the text as a prompt to generate the caption.
inputs = processor(image, text=text, return_tensors="pt")
# Generate caption
outputs = model.generate(**inputs)
# Decode and print caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a photo of a living room with a television and a fireplace此示例展示了编码器-解码器结构的代表性例子,即图像字幕生成。编码器接收图像(BLIP的视觉编码器)并提取特征向量。解码器生成文本(BLIP的文本解码器)。通过注意力机制决定图像特征向量的哪个部分需要关注,同时生成字幕。可以指定影响由文本生成的字幕的提示。BLIP既可以使用图像也可以使用文本作为输入,但这里只使用图像作为输入,并在解码器中生成文本。
10.3.1、10.3.2、10.3.3节中,我们查看了多模态融合的三个核心理论:联合表示、协调表示和编码器-解码器。每种方法都有其自身的特点和优缺点,因此根据应用领域选择合适的方法至关重要。
在多模态深度学习中,“融合(Fusion)”是将不同模态的信息结合起来,创造更丰富和强大的表示的核心过程。10.3节中,我们简要地介绍了基于CMU讲座的融合理论,但实际的多模态融合研究更加多样化和动态。在这个深度探讨中,我们将深入分析融合的各种分类体系和最新研究动态,并看看2025年当前哪些技术受到关注。
多模态融合不能仅凭一个标准来分类。研究人员从不同的角度出发,分类融合方式,每一种分类都不是相互排斥,而是相互补充的。
这种分类关注多模态深度学习模型中的“哪个阶段”进行融合。(参考10.3.4节)
Early Fusion(早期融合):在模型的输入阶段,结合各个模态的“原始”数据(或非常早期处理的特征)。
Late Fusion(晚期融合):分别处理每个模态,然后在最后阶段结合各个模型的输出(例如预测结果)。
Hybrid Fusion(混合融合):Early Fusion和Late Fusion的结合。在模型的多个阶段进行融合,以便利用不同层次的信息。
Model-Agnostic Fusion:不依赖于特定模型的一般融合技术(Early、Late、Hybrid Fusion等)。
Model-Specific Fusion:针对特定模型结构优化的融合技术。
最新研究: 2025年6月11日-12日に開催予定のCVPRワークショップ(MULA 2025)では、自律走行分野でさまざまなセンサデータ(カメラ、LiDAR、レーダー等)を効果的に融合するためのモデル構造に関する研究が議論される予定です。このワークショップは、コンピュータビジョン、MULTIMEDIA、リモートセンシング、ロボティクスコミュニティ間の学際的な相互作用と協力を促進することを目的としており、特に自律走行分野でのマルチモーダルアプローチに大きな関心が集まっています。
对称的(Symmetric)与不对称的(Asymmetric)融合:
对称的: 所有模态都被等同地对待。
不对称的: 特定的模态被赋予更大的权重或不同的角色。
最新研究: “Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion”提出了一种在单一网络内从多个层次融合多模态特征的有效框架。该研究引入了两个不对称融合操作:通道混洗和像素偏移,以便沿着不同的融合方向学习不同特征。此外,2025年1月发表的”Multimodal sentiment analysis based on multi-layer feature fusion”提出了一个新的方法,以实现准确的情感分析,特别是在模态不平衡和隐式表示条件下。
显式(Explicit)与隐式(Implicit)融合:
显式: 模态之间的关系被明确定义或建模。(例如:注意力机制)
隐式: 模态之间的关系没有直接定义,模型通过学习来发现这种关系。(例如:简单组合)
最新研究: HCI International 2025会议(25年6月)将发表一项比较显式融合和隐式融合优缺点的研究。
2024-2025年的研究中,最引人注目的融合方式是基于注意力的机制。
概念: 使用一个模态的特征作为查询(query),应用于另一个模态的特征(key-value)上。 (参见10.4.2节)这样,模型可以精细地捕捉一个模态的特定元素与另一个模态的哪些元素相关。
优点: 能够捕捉模态之间的细致和灵活的关系。例如,在图像字幕生成中,当生成“正在奔跑”的词语时,模型可以专注于图像中狗“奔跑”的动作对应的区域。
最新研究
2025年1月发表的”Bi-Att3DDet”研究引入了双向注意力融合方式,用于自律走行中的3D物体检测。该研究提出了一种双向交互方式,以最大限度地利用LiDAR和摄像头数据之间的互补信息。
2024年3月发表、2025年2月修订的”LANMSFF”研究结合了轻量注意力网络和多尺度特征融合,用于多视点面部表情识别。这种方法同时生成通道和空间注意力图,以强调重要特征并抑制不相关特征。
最近的神经科学研究(2025年)调查了跨模态一致性对感官信息处理和积累的影响。该研究表明,听觉和视觉刺激之间的一致性在感官处理的早期阶段起着重要作用。 #### 2.2 多头注意力
概念: 使用多个注意力头来从不同角度捕捉模态间的关系。每个头使用不同的权重矩阵(W_Q, W_K, W_V)来转换输入数据并计算注意力,因此每个头可以关注输入数据的不同方面(例如,语义、语法结构、风格)。
优点: 可以同时建模多种类型的关系,从而学习更丰富和复杂的表示。例如,在融合图像和文本时,一些头可以关注图像中的对象与文本中的单词之间的关系,而其他头可以关注图像的整体氛围与文本的语气之间的关系。
最新研究:最近的大规模多模态模型(LMM)进一步扩展和完善了这种技术,有效地建模了图像、文本、音频、视频等不同模态之间的复杂交互。
对比学习(Contrastive Learning):
基于掩蔽的学习(Masking-based Learning):
令牌级别融合(Token-level Fusion): 对每个模态的个体令牌(例如图像补丁、文本令牌)进行细粒度的交互建模。
实例级别融合(Instance-level Fusion): 将每个模态的整个实例(例如整个图像、整个文本)视为一个单元来进行融合。
多模态融合可以通过不同的方式分类,每种分类方法提供了不同的视角。实际研究中经常将这些分类方法结合使用。 2025年現在,多模態融合研究關注於令牌級別的細膩交互作用、跨注意力機制、自監督學習方法等高效融合技術的開發。特別是在CVPR 2025研討會(25年6月,納什維爾)等主要學術活動中,將會充分探討多模態融合技術在自駕車、醫療診斷、材料科學等各個應用領域的發展。
通過這次深入介紹,我們可以理解多模態融合的不同類別及其特點,从而更深入地分析後續介紹的多種多模態模型。
严格指令:
$...$ 或 $$...$$ 包围的 LaTeX 数学表达式。将它们保持原样。|、连字符 -、冒号 :)完全相同。仅翻译表格单元格内的文本内容。从10.3.1节到10.3.3节,我们探讨了多模态数据融合的方法。这是一个理论上的分类。在设计实际的多模态模型时,需要根据给定的问题和数据特征来决定采用什么样的融合方式、在什么时候应用以及如何应用。本节将介绍最新的多模态模型采用的复杂模态性整合策略。
早期融合是在模型的早期阶段结合多个模态的输入。最简单的形式是连接各个模态的特征向量。早期融合的优点是可以轻松地捕捉模态之间的低级相互作用。例如,如果图像的颜色和文本的特定单词有很强的关联,则可以通过早期融合来容易地学习这种关系。但是,它可能不能充分利用每个模态的特性,特别是在需要针对每个模态进行专门处理的情况下(例如:图像使用CNN,文本使用RNN),早期融合可能效率低下。
最近的研究中,不仅提出简单连接,还提出了验证早期融合在具有不确定性的多模态数据环境中的有效性基准测试。
让我们看一个早期融合的简单例子。Joint Representation中使用concatenation进行早期融合。相同的代码被使用。在最后,使用一个简单的线性分类器来判断是否有猫。
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# 이미지와 텍스트를 위한 사전 학습된 모델 및 프로세서/토크나이저 로드
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# 예제 이미지 및 텍스트
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 이미지와 텍스트 전처리
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# 각 모달리티에 대한 특징 추출 (임베딩)
with torch.no_grad(): # 기울기 계산 비활성화 (추론 모드)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
# Joint Representation 생성 (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # 이미지 특징 벡터 크기
print("Text Features Shape:", text_features.shape) # 텍스트 특징 벡터 크기
print("Joint Representation Shape:", joint_representation.shape) # 결합된 특징 벡터 크기 (image + text)
# Joint Representation을 활용한 추가 작업 (예: 분류)
num_labels = 2 # 예: "고양이 없음(0)" "고양이 있음(1)", 두 가지 클래스로 분류
classifier = torch.nn.Linear(joint_representation.size(1), num_labels) # 간단한 선형 분류기
outputs = classifier(joint_representation)
print("Classification Outputs:", outputs)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])
Classification Outputs: tensor([[0.1817, 0.0355]], grad_fn=<AddmmBackward0>)在上面的例子中,图像和文本分别是 ViT 和 BERT 这两个单独模型的输出直接结合,没有对这两个向量进行额外的处理(如注意力机制、复杂变换)来结合图像特征和文本特征。因此,这属于早期融合。
晚期融合是指分别使用单独的模型处理每个模态,并在最后阶段将每个模型的输出(例如预测结果)结合起来。这种方法的优点是可以利用针对每个模态特定的模型。例如,可以使用预训练的 CNN 处理图像,使用预训练的 Transformer 处理文本,从而有效地提取每个模态的复杂特征。然而,其缺点是只考虑了模态之间的高层交互,而中间阶段的信息交换较难。
晚期融合与集成(ensemble)方法类似,研究表明通过结合不同模态模型的输出可以提高性能。
混合融合是指同时使用早期融合和晚期融合的方法。在模型的多个阶段进行融合,以利用多种层次的信息。这种方法的优点是可以同时利用早期融合和晚期融合的优势,即,可以考虑模态之间的低层交互和高层交互。然而,其缺点是模型结构变得更加复杂,需要调节的超参数也更多。
混合融合的一个著名例子是跨模态注意力(Cross-Modal Attention)。这种方法使用一个模态的特征作为查询(query),应用于另一个模态的特征(key-value)上。它是在中间阶段进行融合的典型方法。
最近的研究还尝试了除注意力机制以外的其他中间阶段融合方法,例如门控机制(gated mechanism)和双线性池化(bilinear pooling)。
2023年以后,大规模多模态模型(LMM),如Gemini和GPT-4V,引入了更加精细的模态集成策略,从而大幅提高了性能。
选择性融合机制(Selective Fusion Mechanism) 动态判断每个模态的重要性,并有选择地整合信息。例如,当图像中包含文本时,更强烈地关联文本区域的视觉特征和文本内容。这与人类根据情况调整视觉信息和文本信息重要性的方式类似。
动态加权(Dynamic Weighting) 根据任务和输入的特性自动调节每个模态的贡献度。例如,在视觉问答(VQA)任务中,根据问题的性质不同地为图像和文本信息分配不同的权重。“图片的颜色是什么?”这个问题更多地依赖于视觉信息,而“这张图片代表什么意思?”这个问题更多地依赖于文本信息。
任务特定融合方式(Task-Specific Fusion) 根据特定任务的要求优化模态集成方法。例如,在图像标题生成中,重点是从视觉信息到文本的单向转换,而在视觉问答中,则强调双向信息交互。
这些精细的集成策略大幅提高了多模态模型的性能。尤其是,通过超越简单的信息结合,动态调整每个模态的角色和重要性,并根据任务特性优化融合方式,在需要复杂推理的任务中表现出色。 这些整合策略需要大量的数据集和计算资源,因此通过学习示例直接实现和实验是很困难的。相反,通过每个模型的论文和技术文档来获得概念性的理解是更为理想的。
10.3节中,我们探讨了各种理论方法和策略来融合多模态数据。基于此,本节将具体介绍实际的多模态模型如何有效地表示每个模态的信息,并学习不同模态之间的关系。完整的实现可以在chapter_10/multimodal_embeding.py中找到。
多模态学习的一个核心任务是将具有不同特性的模态表示到一个有意义的共同空间中。图像是一维数组,文本是一维序列,音频是时间上的幅度值等,每个模态都有其独特的表示方式。为了有效地处理这些异构数据,我们需要一种可以捕捉每个模态的基本特征并使它们之间具有语义关系的表达学习技术。
早期方法:个别编码器 + 投影
早期的多模态模型使用了针对每个模态的专用编码器(例如,图像使用CNN,文本使用RNN)来提取特征向量,然后通过线性变换或浅层MLP将它们投影到共同维度的向量空间中。(参考10.3.1节中的Joint Representation和Concatenation方法)
最近方法:语义对齐
最近,研究重点转向了使每个模态的特征向量在语义上“对齐”的学习方法。也就是说,相关的图像和文本应该在嵌入空间中彼此接近,而不相关的图像和文本应该相距较远。
对比学习:(参考10.3.2节中的Coordinated Representation和CLIP示例)将图像-文本对视为“正样本”,随机混合的图像-文本对视为“负样本”,通过提高正样本之间的相似度和降低负样本之间的相似度来进行学习。
三元组损失:使用图像锚点、正文本(与图像相关的标题)和负文本(其他图像的标题)的三个元素,通过使锚点图像和正文本之间的距离更近,锚点图像和负文本之间的距离更远来进行学习。
实现示例(对比学习)
class MultimodalEmbedding(nn.Module):
def __init__(self, embedding_dim=512):
super().__init__()
self.image_encoder = models.resnet18(pretrained=True)
self.image_encoder.fc = nn.Sequential(
nn.Linear(512, embedding_dim),
nn.LayerNorm(embedding_dim)
)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_projection = nn.Sequential(
nn.Linear(768, embedding_dim), # BERT output dimension is 768
nn.LayerNorm(embedding_dim)
)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def encode_image(self, image):
return self.image_encoder(image)
def encode_text(self, input_ids, attention_mask):
text_features = self.text_encoder(input_ids, attention_mask)[0][:, 0, :] # [CLS] token, keep batch dim
return self.text_projection(text_features)MultimodalEmbedding 类:
image_encoder:使用 ResNet18 将图像转换为大小为 embedding_dim 的特征向量。text_encoder:使用 BERT 模型将文本转换为特征向量,并通过 text_projection 层调整到大小为 embedding_dim。logit_scale:CLIP 中使用的可学习温度参数。语义对齐机制
语义对齐主要在两个部分实现:MultimodalEmbedding 类的 forward 方法和 constrasive_loss()。
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.transpose(-1, -2)
# print("logits:", logits.shape)
return logits # Return a single valueforward 方法:
使用 encode_image 和 encode_text 分别对图像和文本进行编码。
特征归一化(Feature Normalization):使用 L2 归一化(L2 normalization)将 image_features 和 text_features 向量的大小设置为 1。这是为了仅考虑向量方向计算相似度。
温度缩放(Temperature Scaling):使用 logit_scale 调整相似度得分分布。对 logit_scale 应用指数函数以获得缩放值,然后将其乘以图像特征矩阵和转置的文本特征矩阵的矩阵乘积。矩阵乘积通过计算每个图像特征向量与所有文本特征向量之间的点积来生成相似度得分。
logits:计算图像特征向量和文本特征向量之间的相似度(点积)。使用 text_features.transpose(-1, -2) 代替 text_features.t() 进行转置。交换文本特征矩阵的最后两个维度(批次、文本特征维度)以形成(批次、特征维度、文本)形式,使其可以与(批次、图像特征维度)形式的图像特征矩阵相乘。
def contrastive_loss(logits): # removed enhanced_similarity
labels = torch.arange(logits.size(0), device=logits.device) # Use logits.size(0)
# Image-to-text and text-to-image contrastive loss
img_txt_loss = nn.CrossEntropyLoss()(logits, labels)
txt_img_loss = nn.CrossEntropyLoss()(logits.T, labels)
# Average loss
return (img_txt_loss + txt_img_loss) / 2contrastive_loss 函数会根据 logits 矩阵的大小生成从 0 到(批量大小 - 1)的整数标签。logits 矩阵中的对角线元素(i,i)表示第 i 个图像和第 i 个文本之间的相似度,即图像和文本形成正向配对的相似度,因此会将这些对角线元素设置为正确答案。此外,img_txt_loss 计算从图像到文本的相似度损失(image-to-text loss),而 txt_img_loss 计算从文本到图像的相似度损失(text-to-image loss)。通过平均这些损失,可以同时考虑双向(image-to-text 和 text-to-image)语义对齐。
语义对齐机制将不同模态的特征映射到语义一致的空间中。首先,通过 L2 正则化将所有特征向量投影到单位球面上,以消除模态之间的尺度差异。引入温度缩放参数来调整相似度值的分布。高温会产生更平滑的分布,而低温会产生更尖锐的分布,从而提高训练的稳定性。此外,通过对比学习,使相关图像-文本配对在嵌入空间中靠近,而无关配对则远离。特别地,图像到文本和文本到图像的映射同时被优化,以实现双向语义对齐。
CLIP 的对比学习类似,相关内容会被学习为相近,而不相关内容会被学习为相远。这种基于对比学习的语义对齐策略从 2021 年 OpenAI 的 CLIP 开始发展,包括 Google 的 PaLM-E、Anthropic 的 Claude 和 DeepMind 的 Gemini 等模型。早期的 CLIP 重点关注图像-文本配对的简单对比学习,而最新的模型则更细致地捕捉多个模态之间的相互关系。特别是 Gemini,会同时学习图像、文本、音频和视频等多种模态之间的语义对齐,同时保留每个模态的独特特征并构建一个集成的语义空间。
示例运行
训练使用的数据集为 Flicker8k。可以使用 train_multimodal_embedding 函数来训练 EnhancedMultimodalEmbedding(或 EnhancedMultimodalEmbedding_no_p)模型在 Flicker8k 数据集上。在 main 函数中设置模型、数据加载器、优化器等,然后调用 train_multimodal_embedding 函数即可开始训练。
# download flickr8k.
!mkdir data;cd data;wget "https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip";unzip -q flickr8k.zip -d ./flickr8kmkdir: cannot create directory ‘data’: File exists
--2025-03-09 16:33:12-- https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip
Resolving github.com (github.com)... 20.200.245.247
Connecting to github.com (github.com)|20.200.245.247|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream [following]
--2025-03-09 16:33:12-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream
Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...
Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1112971163 (1.0G) [application/octet-stream]
Saving to: ‘flickr8k.zip’
flickr8k.zip 100%[===================>] 1.04G 56.8MB/s in 19s
2025-03-09 16:33:32 (56.9 MB/s) - ‘flickr8k.zip’ saved [1112971163/1112971163]
import torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
# Assuming dldna.chapter_10.multimodal_embedding is in the same directory or Python path.
# Adjust if necessary (e.g., from multimodal_embedding import ...).
from dldna.chapter_10.multimodal_embedding import Flickr8kDataset, MultimodalEmbedding, train_multimodal_embedding, generate_example
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Replace with the actual path to your image directory
caption_file = './data/flickr8k/captions.txt' # Replace with the actual path to your caption file
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# Model initialization
model = MultimodalEmbedding()
# Model training
train_multimodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'multimodal_embedding_model.pth')
# Example generation
model_path = 'multimodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Epoch 1/3: 15%|█▍ | 147/1012 [00:16<01:36, 8.96it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:53<00:00, 8.90it/s]Epoch 1/3 - Train Loss: 0.9618Epoch 1/3 - Validation Loss: 0.5212
Epoch 1: Saved best model with Validation Loss = 0.5212Epoch 2/3: 52%|█████▏ | 525/1012 [00:59<00:55, 8.84it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 2/3 - Train Loss: 0.3393Epoch 2/3 - Validation Loss: 0.4240
Epoch 2: Saved best model with Validation Loss = 0.4240Epoch 3/3: 34%|███▍ | 347/1012 [00:39<01:15, 8.85it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 3/3 - Train Loss: 0.2313Epoch 3/3 - Validation Loss: 0.3891
Epoch 3: Saved best model with Validation Loss = 0.3891
Image 0:
Top 3 Captions (Image -> Text):
- football players in red congratulate each other as crowds in red cheer behind. (prob: 0.9970)
- a man in black holds up an obama 08 sign. (prob: 0.0023)
- a large group of bicycles racing on the street (prob: 0.0004)
Caption: football players in red congratulate each other as crowds in red cheer behind.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9983)
- Image 17 (prob: 0.0013)
- Image 2 (prob: 0.0001)
跨模态注意力用于有效地建模不同模态之间的关系。它扩展了ViT的自注意力机制,使得图像和文本等异质数据之间可以相互作用。
模态间注意力设计
跨模态注意力具有考虑到各个模态特性的非对称结构。
class CrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.image_proj = nn.Linear(config.image_dim, config.hidden_dim)
self.text_proj = nn.Linear(config.text_dim, config.hidden_dim)
self.attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
def forward(self, image_features, text_features):
image_proj = self.image_proj(image_features)
text_proj = self.text_proj(text_features)
attn_output, _ = self.attention(text_proj, image_proj, image_proj)
return attn_output图像和文本特征被投影到共同的潜在空间中,然后通过多头注意力机制学习两个模态之间的关系。文本特征作为查询,图像特征作为键和值,以使文本关注图像的相关部分。
非对称注意力模式
使用非对称注意力模式来保持每个模态的独特性质,同时实现有效的信息交换。
class HierarchicalCrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.local_image_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.local_text_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.image_to_text_attention = CrossModalAttention(config)
self.text_to_image_attention = CrossModalAttention(config)
self.output_layer = nn.Linear(config.hidden_dim * 2, config.hidden_dim)
def forward(self, image_features, text_features):
local_image = self.local_image_attention(image_features, image_features, image_features)[0]
local_text = self.local_text_attention(text_features, text_features, text_features)[0]
image_attended_text = self.image_to_text_attention(image_features, local_text)
text_attended_image = self.text_to_image_attention(text_features, local_image)
combined_features = torch.cat([image_attended_text, text_attended_image], dim=-1)
output = self.output_layer(combined_features)
return output这里分别进行图像到文本、文本到图像的双向注意力机制。通过这样,可以使得每个模态都能选择性地关注相应模态的相关信息。
层次注意力结构
为了捕捉复杂的多模态关系,采用了层次化的注意力机制结构。底层处理每个模态内部的局部特征,而高层则建模模态之间的全局关系。这种层次结构在GPT-4V和Gemini等模型中发挥着核心作用。
class EnhancedMultimodalEmbedding_no_p(MultimodalEmbedding):
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = self.image_preserve(image_features)
text_features = self.text_preserve(text_features)
combined_features = self.cross_modal_attention(image_features, text_features)
combined_features = combined_features / combined_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * combined_features @ combined_features.t()
return logitsimport torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from collections import namedtuple
from dldna.chapter_10.crossmodal_attention import Flickr8kDataset, CrossModalEmbedding, train_crossmodal_embedding, generate_example
# Configuration
config = namedtuple('Config', ['embedding_dim', 'image_dim', 'text_dim', 'hidden_dim', 'num_heads'])(
embedding_dim=512, # Output embedding dimension
image_dim=512, # ResNet18 image encoder output dimension
text_dim=512, # Text feature (768 from BERT -> 512 after projection)
hidden_dim=512, # Cross-modal attention internal hidden dimension
num_heads=8 # Number of multi-head attention heads
)
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4, pin_memory=True)
# Model initialization
model = CrossModalEmbedding(config)
# Model training
train_crossmodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'crossmodal_embedding_model.pth')Epoch 1/3: 4%|▍ | 40/1012 [00:04<01:41, 9.53it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:47<00:00, 9.41it/s]Epoch 1/3 - Train Loss: 0.9663Epoch 1/3 - Validation Loss: 0.5378Epoch 2/3: 58%|█████▊ | 582/1012 [01:02<00:45, 9.36it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.31it/s]Epoch 2/3 - Train Loss: 0.3381Epoch 2/3 - Validation Loss: 0.4452Epoch 3/3: 0%| | 4/1012 [00:00<02:27, 6.82it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.35it/s]Epoch 3/3 - Train Loss: 0.2288Epoch 3/3 - Validation Loss: 0.3743# Example generation
model_path = 'crossmodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Image 0:
Top 3 Captions (Image -> Text):
- two people walk out onto the desert sand. (prob: 0.9862)
- a man takes a picture of him and his friend with his phone. (prob: 0.0092)
- the little boy wearing the blue shirt is putting dirt in his mouth. (prob: 0.0013)
Caption: two people walk out onto the desert sand.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9898)
- Image 2 (prob: 0.0089)
- Image 4 (prob: 0.0005)
Perceiver 是 2021 年 DeepMind 提出的多模态架构。它解决了现有 Transformer 的二次复杂度问题(输入序列长度增加,计算量呈平方增长),同时提供了一种可以有效处理各种模态(图像、文本、音频、点云等)的结构。Perceiver 特别适用于输入数据大小很大的情况(例如高分辨率图像、长文本)。这里我们将描述整个架构,并省略示例。代码仅为说明目的的示例代码。
Perceiver 的核心思想
Perceiver 基于以下思想:
Perceiver 无论输入序列长度如何,都使用固定大小的潜在向量(latent array)。该潜在向量压缩并表示输入数据信息,类似于瓶颈,将大量输入信息总结为少量潜在向量。因此,即使输入数据大小很大(例如 10,000 个 token),由于潜在向量的数量是固定的(例如 256),可以大大减少计算复杂度和内存使用。
class Perceiver(nn.Module):
def __init__(self, ..., num_latents=256, latent_dim=512, ...):
super().__init__()
# Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# ...在上面的代码中,self.latents 就是表示那个潜在向量的。它被定义为 nn.Parameter,因此是一个可学习的参数。
Perceiver 不使用针对特定输入模态(如图像、文本、音频等)的专用处理方式(例如 CNN、RNN)。相反,每个模态经过简单的预处理(例如图像补丁、文本分词)后,都会被转换为一个共同的形式(向量序列)。然后,Perceiver 使用相同的基于 Transformer 的架构(交叉注意力、自注意力),无论输入模态的类型如何,都可以进行统一的处理。这使得 Perceiver 能够灵活地处理各种模态,并且容易添加新的模态。
Perceiver 使用多层自注意力机制逐步更新潜在向量。在每一层中,潜在向量之间交换信息,以学习输入数据的复杂模式。最初表示简单特征的潜在向量,经过多层处理后,逐渐表达出抽象和高级的意义。
Perceiver 的工作方式(简化代码示例)
import torch
import torch.nn as nn
class Perceiver(nn.Module):
def __init__(self,
input_channels=3, # Input channels (e.g., RGB image)
input_axis=2, # Input dimension (image=2, video=3)
num_latents=256, # Number of latent vectors
latent_dim=512, # Latent vector dimension
num_heads=8, # Number of attention heads
depth=6): # Model depth (number of self-attention layers)
super().__init__()
# 1. Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# 2. Input projection (matches input dimension to latent dimension)
self.input_proj = nn.Linear(input_dim, latent_dim)
# 3. Cross-Attention (learns relationships between input and latent vectors)
# self.cross_attention = nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
# 4. Self-Attention (learns relationships between latent vectors) - repeated multiple times
self.self_attention_layers = nn.ModuleList([
nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
for _ in range(depth)
])
def forward(self, x): # x: Input data (image, text, ...)
batch_size = x.shape[0]
# 1. Input projection
x = self.input_proj(x)
# 2. Latent vector replication (for each item in the batch)
latents = self.latents.unsqueeze(0).expand(batch_size, -1, -1) # (B, num_latents, latent_dim)
# 3. (Optional) Cross-attention (between input and latent vectors)
# latents, _ = self.cross_attention(latents, x, x) # query, key, value
# 4. Self-attention (between latent vectors) - repeated multiple times
for layer in self.self_attention_layers:
latents, _ = layer(latents, latents, latents) # query, key, value
return latents # Return the processed latent vectorsPerceiver的優缺點
Perceiver具有計算複雜度幾乎不變的效率,並可以以相同方式處理不同的模態,提供了靈活性。此外,新增模態容易的可擴展性也是Perceiver的優點。但是,Perceiver仍然基於Transformer,因此結構複雜,潛在向量的維度和層數增加時,模型可能會變得非常大。另外,在圖像分類等特定任務中,與CNN等專門為該任務設計的模型相比,性能可能會降低。
Perceiver IO
作為Perceiver的後續研究,Perceiver IO提出了一種不僅處理輸入還對輸出進行潛在向量處理的方法。通過這種方式,可以靈活地處理多種輸出形式(分類、回歸、序列生成等)。Perceiver IO被評為比Perceiver更為通用和強大的模型。
这里,我们从跨模态注意力的基本结构开始,逐渐添加机制,并比较其训练可能性和性能。通过这种方式,我们可以了解多模态学习中出现的问题,并探讨解决这些问题的实用方法。
设计跨模态注意力机制时,以这种逐步增加复杂度的实验方式是非常常见和推荐的方法。这种被称为消除研究(Ablation study)的方法,对于了解每个组成机制的重要性以及确定最终模型性能的核心要素非常有效。许多提议新架构的论文都使用这种方法。此外,不仅讨论最终的性能,还一起讨论训练过程中的稳定性问题,从实践角度来说是非常重要的。
比较训练方式
实验使用之前查看过的flickr8k数据集,拥有文本和图像两个输入,并训练它们之间的相似度。训练中,跨模态注意力的版本是固定的,每个版本的复杂度都会增加。每次添加一个跨模态注意力的机制,然后进行训练以便比较。所有训练使用相同的超参数。训练epochs被固定为5。
示例结构
示例采用如下结构:
chapter_10/mm
├── cat_resized.png
├── cross_attention
│ ├── v0.py
│ ├── v1.py
│ ├── v2.py
│ ├── v3.py
│ .... (continue to exist)
├── train_multimodal.py
└── evaluate_models.py
cross_attention 文件夹下,从 v1 到 v11 顺序地增加了跨注意力的复杂度。 train_mulimodal.py 会在一个训练完成后动态生成下一个版本的模型并继续训练。在训练中,记录准确率、对比损失、执行时间等指标,以生成最终比较表。仅凭损失值和准确率来判断是否可以进行训练是不够好的,因为对比学习的特性,使得用现有数据无法确认训练是否正确进行。确认训练是否成功的最简单方法是使用以前没有的数据进行评估。零样本(zero-shot)评估模型的文件是 evalute_models.py。
被评估的图像是:

评估的方式是测量 5 段文本与上述图像的相似度。
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]如果模型训练正确,则 5 个字幕中,第二个 “A cat sleeping on a couch” 应该具有最高的相似度。上述图像是训练数据中不存在的,属于典型的零样本测试。
跨注意力动态分配
cross_attion的版本通过动态分配来改变。
from dldna.chapter_10.mm.cross_attention.v0 import CrossAttention as v0
from dldna.chapter_10.mm.cross_attention.v1 import CrossAttention as v1
# ... (import other versions) ...
from dldna.chapter_10.mm.cross_attention.v11 import CrossAttention as v11
def get_cross_attention(version, config=None):
if config is None:
config = {}
if version == 'v0':
return v0(**config)
elif version == 'v1':
return v1(**config)
# ... (other version conditions) ...
elif version == 'v11':
return v11(**config)
else:
raise ValueError(f"Invalid cross-attention version: {version}")
# ...
class ImageTextMatchingModel(nn.Module):
def __init__(self, image_encoder_dim=2048, text_encoder_dim=768, projection_dim=256):
super().__init__()
self.image_encoder = ImageEncoder(image_encoder_dim, projection_dim)
self.text_encoder = TextEncoder(text_encoder_dim, projection_dim)
# The CrossAttention module is dynamically assigned in main().
self.cross_attention = None # CrossAttention(projection_dim)
def forward(self, image, input_ids, attention_mask):
# ...
image_attended, text_attended = self.cross_attention(
image_features.unsqueeze(1),
text_features.unsqueeze(1)
)
# ...
# ...
def run_training(model_versions, ...):
# ...
for model_version in model_versions:
# ...
# Model initialization
model = ImageTextMatchingModel()
# Dynamically load the CrossAttention module
model.cross_attention = get_cross_attention(model_version, config=config)
# ...该部分实现了实验核心中的各种版本的 Cross-Attention 模块的动态加载和应用逻辑。get_cross_attention 函数接受字符串形式的版本(v0、v1、…、v11)作为输入,并返回对应版本的 CrossAttention 类的实例。在 run_training 函数内部,对于 model_versions 列表中指定的每个版本,初始化 ImageTextMatchingModel,并通过调用 get_cross_attention 函数将该版本的 Cross-Attention 模块分配给 model.cross_attention。
这种动态分配方式提高了代码的复用性,并使实验管理变得更加容易。当添加新的 Cross-Attention 版本时,只需要在 get_cross_attention 函数中添加该版本,因此无需大幅修改训练代码。另外,通过 run_training 函数中的 model_versions 列表,可以轻松控制要训练的版本。
Contrastive Loss 计算与训练循环
def contrastive_loss(logits):
labels = torch.arange(len(logits), device=logits.device)
loss_i = nn.CrossEntropyLoss()(logits, labels)
loss_t = nn.CrossEntropyLoss()(logits.t(), labels)
return (loss_i + loss_t) / 2
def train(model, train_loader, val_loader, epochs=10, lr=1e-4, model_version='v0'):
# ...
for epoch in range(epochs):
model.train()
total_loss = 0
# ...
for batch in tqdm(train_loader, ...):
images, input_ids, attention_mask = [x.to(device) for x in batch]
optimizer.zero_grad()
logits = model(images, input_ids, attention_mask)
loss = contrastive_loss(logits)
loss.backward()
optimizer.step()
total_loss += loss.item()
# ... (validation 및 지표 계산) ...本部分定义了模型的训练中使用的对比损失计算和训练循环。contrastive_loss 函数接受图像-文本对的相似度得分(logits)作为输入,计算对比损失。此时,正确标签是 logits 的对角线(即相同索引的图像-文本对)中元素为 1(相似),其余为 0(不相似)(使用 torch.arange)。计算以图像为基础的交叉熵损失(loss_i)和以文本为基础的交叉熵损失(loss_t),并将这两个损失的平均值用作最终损失。
训练方式:机制的添加
我们将从最简单的注意力结构开始,一步一步地添加功能进行测试。添加的功能称为“机制”。当每个机制被添加时,我们将研究它如何影响多模态注意力设计。首先,我们来看看部分训练代码,然后直接看训练结果。在此之后,我们还将研究哪些机制在跨模态注意力的训练中起到了决定性的作用。
以下是训练代码。当进行训练时,每个模型都将以 model_final_{版本}.pth 的形式保存。使用这个保存的模型来执行评估。
from dldna.chapter_10.mm.train_multimodal import run_training
# model_versions = ['v0', 'v1'] # List of model versions to train
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
epochs = 5
lr = 1e-4
# Dataset
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
results_df = run_training(model_versions, epochs=epochs, lr=lr, image_dir=image_dir, caption_file=caption_file) # Train multiple versions
# Print results
print("\nTraining Results:")
# Print results in Markdown table format
print(results_df.to_markdown(index=False))模型进行评估。
from dldna.chapter_10.mm.evaluate_models import evaluate_all_models
# Test captions (fixed)
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]
# Run model evaluation
image_path = './cat_resized.png'
model_dir = '.'
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
results_df = evaluate_all_models(model_dir, image_path, test_captions, model_versions)
# Print results (Markdown table)
print(results_df.to_markdown(index=False))
# Print results (detailed)
for _, row in results_df.iterrows():
print(f"\nModel: {row['model_version']}")
print(f" Best Caption: {row['best_caption']}")
print(f" Trained Well: {row['trained_well']}")
print(f" Similarity Ratio: {row['similarity_ratio']}")
print(f" Similarity Gap: {row['similarity_gap']}")
print(" All Similarities:")
for caption, sim in zip(test_captions, row['all_similarities']):
print(f" - {caption:<30}: {sim}")| model_version | best_caption | all_similarities | similarity_ratio | similarity_gap | trained_well | similarity_ratio_rank |
|---|---|---|---|---|---|---|
| v0 | 猫睡在沙发上 | [‘5.322’, ‘15.477’, ‘-4.509’, ‘-6.609’, ‘2.107’] | 2.908 | 10.155 | True | 1 |
| v1 | 猫睡在沙发上 | [‘3.117’, ‘18.174’, ‘-6.475’, ‘-1.825’, ‘8.705’] | 2.088 | 9.469 | True | 3 |
| v2 | 猫睡在沙发上 | [‘3.085’, ‘12.541’, ‘-4.252’, ‘0.924’, ‘6.849’] | 1.831 | 5.692 | True | 5 |
| v3 | 孩子们踢足球 | [‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’] | 1 | 0 | False | 14 |
| v4 | 猫睡在沙发上 | [‘7.385’, ‘8.301’, ‘-1.038’, ‘-6.262’, ‘1.240’] | 1.124 | 0.915 | True | 12 |
| v5 | 孩子们踢足球 | [‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’] | 1 | 0 | False | 14 |
| v6 | 猫睡在沙发上 | [‘5.022’, ‘14.861’, ‘-5.370’, ‘-8.630’, ‘9.063’] | 1.64 | 5.798 | True | 7 |
| v7 | 狗在公园里玩耍 | [‘16.300’, ‘16.300’, ‘16.300’, ‘16.300’, ‘16.300’] | 1 | 0 | False | 14 |
| v8 | 猫睡在沙发上 | [‘9.841’, ‘15.442’, ‘-7.350’, ‘-1.249’, ‘11.023’] | 1.401 | 4.419 | True | 10 |
| v9 | 猫睡在沙发上 | [‘10.382’, ‘15.192’, ‘-5.582’, ‘-1.594’, ‘5.953’] | 1.463 | 4.81 | True | 9 |
| v10_1 | 狗在公园里玩耍 | [‘0.940’, ‘0.472’, ‘-0.554’, ‘0.334’, ‘-0.111’] | 1.991 | 0.468 | False | 4 |
| v10_2 | 猫睡在沙发上 | [‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’] | 1 | 0 | True | 14 |
| v10_3 | 猫睡在沙发上 | [‘5.913’, ‘10.334’, ‘-5.989’, ‘-1.024’, ‘5.151’] | 1.748 | 4.421 | True | 6 |
| v10_4 | 猫睡在沙发上 | [‘5.913’, ‘10.334’, ‘-5.989’, ‘-1.024’, ‘5.151’] | 1.748 | 4.421 | True | 6 |
| v10_5 | 猫睡在沙发上 | [‘6.601’, ‘9.990’, ‘-5.984’, ‘-2.988’, ‘-0.070’] | 1.513 | 3.389 | True | 8 |
| v10_6 | 狗在公园里玩耍 | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
| v11 | 猫睡在沙发上 | [‘11.315’, ‘15.491’, ‘-10.428’, ‘-0.004’, ‘10.014’] | 1.369 | 4.175 | True | 11 |
根据这些实验结果,我们可以分析每个跨模态注意力版本的训练结果,并总结成功/失败的原因如下。
| 版本 | 注意力结构 | 关键特征 | 训练结果 | 详细说明 |
|---|---|---|---|---|
| v0 | 独立双向注意力 | 仅使用缩放点积注意力 | 训练成功 | 最基本的结构。独立计算图像和文本的注意力。除了缩放外没有其他归一化/变换。由于缺乏单独的归一化,对输入特征尺度变化敏感。 |
| v1 | 共享注意力 | 单一注意力矩阵和转置矩阵 | 训练成功 | 图像→文本和文本→图像的注意力计算共享相同的注意力矩阵。尝试双向信息交换,但由于缺乏归一化仍对输入尺度敏感,且无法正确反映两种模态之间的非对称关系。 |
| v2 | 共享注意力 + LN | 对输入应用LayerNorm | 训练成功 | 对输入特征应用LayerNorm以稳定特征尺度。解决了v1的问题(输入尺度敏感性)。注意力矩阵仍然共享。 |
| v3 | v2 + 残差连接 | 在输出添加残差连接 | 训练失败 | 添加了在注意力计算后直接加上原始特征(image_features, text_features)的残差连接。这过度保留了原始特征,阻碍了通过模态间交互创建新特征。这种现象在浅层网络结构中尤为明显。 |
| v4 | v2 + 投影 | 模态特定的线性变换 | 训练成功 | 对每个模态应用独立的线性投影(self.image_proj, self.text_proj)。通过对归一化输入(image_norm, text_norm)应用单独的线性变换,更灵活地调整每个模态的特征空间,并将其转换为适合注意力计算的形式。 |
| v5 | v2 + 混合比率 | 固定0.5混合比率 | 训练失败 | 以固定比率(0.5)混合原始特征(image_norm, text_norm)和注意力输出(image_attended, text_attended)。与残差连接(v3)类似保留原始特征,但固定的混合比率限制了模型根据数据灵活调整权重的能力。 |
| v6 | 共享注意力 + Q/K/V | Q/K/V变换和单一LayerNorm | 训练成功 | 为输入(image_norm, text_norm)添加生成查询(Q)、键(K)和值(V)的单独线性变换(self.to_q, self.to_k, self.to_v)。这使注意力机制能够学习更丰富的特征表示。仍使用共享注意力矩阵。 |
| v7 | 共享多头 | 多头 + 输出归一化 | 训练失败 | 将共享注意力矩阵扩展为多头注意力。保持输入的LayerNorm(v2)。虽然每个头可以学习不同的特征,但仍使用共享注意力,无法正确建模图像→文本和文本→图像之间的非对称关系。尽管对输出应用了LayerNorm,训练仍然失败。 |
| v8 | 独立多头 | 独立双向多头 + 双重归一化 | 训练成功 | 将图像→文本和文本→图像注意力分离为独立的多头注意力。对输入和输出都应用LayerNorm。在保留每个模态特性的同时有效执行双向信息交换。 |
| v9 | v8 + Pre-LN + FFN | 添加门控FFN和dropout | 训练成功 | 在v8结构上添加前置层归一化、门控前馈网络(FFN)和dropout。Pre-LN在注意力和FFN之前应用LayerNorm以提高训练稳定性。门控FFN使用GELU激活函数和dropout增强非线性并防止过拟合。仅对FFN输出应用残差连接以改善信息流。 |
| v10_1 | v9 + 模态特定Q/K/V | 每个模态的专门变换 | 训练失败 | 基于v9,为每个模态使用单独的Q、K、V投影(self.image_to_q, self.image_to_k, …, self.text_to_v)。这大大增加了模型复杂度,但过度分离了每个模态的特性,使学习两个模态之间的交互变得困难。 |
| v10_2 | v9 + 交叉门控 | 控制模态间信息流 | 训练失败 | 在v9上添加交叉门控机制。在连接注意力输出和原始特征后应用门控层(sigmoid)以控制模态间信息交换。然而,由于缺乏门控层的归一化且初始门控值很小(self.gate_scale = 0.1),无法有效控制信息流并阻碍学习。 |
| v10_3 | v9 + 上下文层 | 处理模态特定的上下文信息 | 训练成功 | 在v9上添加模态特定的上下文层(self.image_context, self.text_context)。这额外处理每个模态的特征,在注意力计算前提供更丰富的上下文信息。 |
| v10_4 | v9 + 多查询 | K,V共享的注意力方法 | 训练成功 | 在v9中引入多查询注意力(Multi-Query Attention)机制。每个头独立维护查询,而所有头共享键和值(self.to_kv)。这减少了参数数量,同时允许每个头从不同角度生成查询以捕获多样化特征。 |
| v10_5 | v9 + 分层多头 | 3级特征处理,基于权重的融合 | 训练成功 | 在v9中引入分层多头注意力结构。将输入特征分为3个级别处理(self.level_projections, self.level_norms)。在每个级别执行独立的多头注意力,并使用可学习权重(self.level_weights)融合各级别的输出。这使模型能够学习各种抽象级别的特征并有效结合它们。 |
| v10_6 | v9 + 对比学习多头 | 基于对比学习的相似度约束,特征增强 | 训练失败 | 在v9上添加用于对比学习的单独投影层(self.contrast_proj)。计算归一化对比学习特征之间的相似度,并通过直接添加到原始特征的方式增强注意力输出。然而,这扭曲了原始特征,类似于v3,阻碍了模态间交互,导致训练失败。 |
| v11 | v9 + 多查询 + 分层融合 | 结合K,V共享与3级特征处理 | 训练成功 | 结合了v10_4(多查询)和v10_5(分层多头)的优势。通过多查询注意力提高参数效率,通过分层融合整合各种级别的特征。保持v9的稳定化技术,如Pre-LN、门控FFN和dropout。 |
1. v0: 独立的双向注意力 - 基本结构
v0 实现了最基本形式的跨模式注意力(Cross-Modal Attention)。它分别为图像和文本计算独立的注意力,并且除了缩放点积注意力(Scaled Dot-Product Attention)以外,不使用其他归一化或变换。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
def forward(self, image_features, text_features):
# Image -> Text attention
attn_i2t = torch.matmul(image_features, text_features.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, text_features)
# Text -> Image attention
attn_t2i = torch.matmul(text_features, image_features.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, image_features)
return image_attended, text_attendedv0因为没有单独的归一化过程,所以对输入特征的尺度变化很敏感。如果输入数据的尺度在训练过程中发生了很大的变化,注意力权重可能会变得不稳定,训练可能无法正常进行。
2. v2: 共享注意力 + 层归一化
v2是在v1的基础上,对输入特征应用层归一化(LN)以稳定特征尺度的版本。v1在计算图像到文本、文本到图像的注意力时,使用相同的注意力矩阵(权重矩阵)和其转置矩阵,但是它对输入尺度很敏感,这是一个缺点。
import torch
import torch.nn as nn
import torch.nn.functional as F
# Co-attention + added LN
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion (without residual connection)
image_out = torch.matmul(attn, text_norm)
text_out = torch.matmul(attn.transpose(-2, -1), image_norm)
return image_out, text_outimage_norm = self.norm(image_features) 和 text_norm = self.norm(text_features) 中对输入特征应用层归一化。层归一化对于每个样本(在小批量内的每个图像或文本)独立地执行归一化。即,计算每个样本的特征向量的均值和方差,使其变为 0 和 1。这样,即使输入特征的尺度发生很大变化,也可以防止注意力权重发散,从而稳定训练。
然而,这仍然存在局限性。v2 通过层归一化解决了输入尺度问题,但使用相同的注意力矩阵对图像到文本和文本到图像注意力进行处理。这可能无法充分反映两个模态之间的非对称关系。从图像生成文本和从文本生成图像是具有不同复杂性的,因此使用相同的注意力机制来处理它们可能是低效的。
3. v3: v2 + 残差连接(Residual Connection)- 失败案例
在 ResNet 模型架构之后,残差连接被广泛使用,但是在这里却成了失败的原因。残差连接通常用于缓解网络加深时可能出现的梯度消失问题,并且是有效地学习更深层次网络的常用技术。但是,在这个实验中,残差连接反而表现出降低性能的失败案例。
这是一个非常重要的观察。
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion
image_attended = torch.matmul(attn, text_norm)
text_attended = torch.matmul(attn.transpose(-2, -1), image_norm)
# Add residual connection
image_out = image_features + image_attended
text_out = text_features + text_attended
return image_out, text_out一般来说,残差连接在解决网络加深时学习变得更加困难的问题方面是有效的。但是在v3中,由于以下原因,反而导致了性能下降的结果。
相对较浅的网络: v3模型具有相对较浅的网络结构。残差连接在深度网络中可以缓解梯度消失问题,但在浅层网络中,其效果甚微,甚至可能会阻碍信息流动。
原始特征的过度保留: 跨模态注意力机制(Cross-Modal Attention)的核心是通过图像和文本之间的交互作用产生新的特征。但是在v3中,直接将原始特征向量添加到注意力运算结果中,从而稀释了注意力机制所获得的重要信息,并阻碍了两个模态之间的交互作用所产生的特征生成。也就是说,模型更专注于保持现有信息,而不是学习新的信息。
v3的实验结果告诉我们,残差连接并不是一个总能提高性能的万能解决方案。残差连接需要根据网络深度、应用位置以及问题特点等因素进行慎重使用。v3是由于滥用残差连接导致性能下降的典型失败案例。
4. v8: 独立多头注意力
v8引入了一个重要的变化来解决之前版本(v7)的问题并提高跨模态注意力的性能。具体来说,就是将图像到文本的注意力和文本到图像的注意力分离为独立的多头注意力(Multi-Head Attention)。此外,不仅对输入进行Layer Normalization,还对注意力运算的输出进行Layer Normalization,以进一步增强训练的稳定性。
import torch
import torch.nn as nn
import torch.nn.functional as F
# v8 - Independent multi-head
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Add output normalization
self.out_norm = nn.LayerNorm(dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
image_out = self.out_norm(self.to_out(image_attended))
text_out = self.out_norm(self.to_out(text_attended))
return image_out, text_outv7引入了多头注意力机制,但在图像→文本和文本→图像的注意力计算中仍然使用相同的Q、K、V变换。也就是说,由于所有头部共享相同的Q、K、V矩阵,每个头部学习不同特征的能力受到了限制,这成为了制约模型表达能力的因素。v8为了解决这个问题,对每个方向(图像→文本、文本→图像)和每个头部应用了独立的Q、K、V变换,使模型能够学习更加灵活和丰富的特征表示。
5. v9: v8 + Pre-LN + FFN(门控FFN + Dropout)
v9在v8结构的基础上,添加了三个重要机制以进一步提高训练稳定性和性能:Pre-Layer Normalization(前置层归一化)、门控前馈神经网络(Gated FFN)和Dropout(随机失活)。
import torch
import torch.nn as nn
import torch.nn.functional as F
# v9 - Dropout before gated FFN, pass through norm at the end -> trainable
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, dropout=0.1, ff_dim=None):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
ff_dim = ff_dim or dim * 4
# Normalization layers for Pre-LN
self.attn_norm = nn.LayerNorm(dim)
self.ff_norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Dropout
self.dropout = nn.Dropout(dropout)
# Gated feedforward network
self.ff_gate = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_value = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_out = nn.Linear(ff_dim, dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Pre-LN: Normalize before attention
image_norm = self.attn_norm(image_features)
text_norm = self.attn_norm(text_features)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
attn_i2t = self.dropout(attn_i2t) # Apply dropout to attention weights
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
attn_t2i = self.dropout(attn_t2i) # Apply dropout to attention weights
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
# Output projection and dropout
image_attended = self.dropout(self.to_out(image_attended))
text_attended = self.dropout(self.to_out(text_attended))
# Residual connection - connecting the original image features makes training impossible.
# image_attended = image_attended + image_features
# text_attended = text_attended + text_features
# Pre-LN: Normalize before FFN
image_ff = self.ff_norm(image_attended)
text_ff = self.ff_norm(text_attended)
# Gated feedforward processing
def apply_ff(x):
gate = self.ff_gate(x)
value = self.ff_value(x)
return self.dropout(self.ff_out(gate * value))
# FFN output and residual connection - this type of residual connection is possible.
image_out = apply_ff(image_ff) + image_attended
text_out = apply_ff(text_ff) + text_attended
return image_out, text_out预归一化(Pre-Layer Normalization):在v8中,注意力运算之后应用层归一化(Post-LN),而在v9中,之前应用(Pre-LN)。self.image_norm_q、self.image_norm_k、…、self.text_norm_v属于此类。预归一化比后续归一化具有更高的训练稳定性,并且不需要单独的warmup,因此在最近的Transformer基于模型中被广泛使用。
门控Feed-Forward Network(FFN):在v8的注意力运算之后添加FFN,以增强非线性并提高模型的表达能力。
self.image_ffn和self.text_ffn定义了FFN。FFN由两个线性层(Linear Layer)、中间的GELU(高斯误差线性单元)激活函数以及dropout组成。self.image_ffn_norm、self.text_ffn_norm)。与v3不同的是,在经过FFN之后应用残差连接,从而实现非线性处理后的信息融合,而不是简单地保留原始特征,这有助于改善信息流动并提高性能。dropout:self.dropout定义了应用于注意力权重和FFN内部的dropout。dropout是一种有效的正则化技术,通过在训练过程中随机禁用神经元来防止模型过拟合(Overfitting)。
添加机制的效果
v9通过这些技术的组合大大提高了跨模态注意力的性能,并成为后续版本的基础。
v0, v1 (基本结构): 没有正则化的简单注意力机制的 v0 和 v1,在训练上是 成功 的。但是,v1 在训练和验证数据集上都表现出对于“猫”相关字幕的更高相似度。这表明了正则化的重要性。
v2 (LayerNorm): 在输入中应用 LayerNorm 的 v2 成功地完成了训练。这表明,稳定输入特征的尺度是很重要的。
v3 (残差连接): 在 v2 基础上添加残差连接的 v3 未能成功地完成训练。这表明,在多模态学习中,残差连接并不总是有帮助的。因为残差连接可能过度保持原始特征,从而阻碍了两个模态之间的交互作用。
v4 (投影): 为每个模态添加独立线性变换(投影)的 v4 成功地完成了训练。这表明,适当地转换每个模态的特征空间是很重要的。
v7 (共享多头): 将共享注意力矩阵扩展为多头的 v7 未能成功地完成训练。这可以解释为,每个头都没有正确反映不同模态的特性。
v8 (独立多头): 为每个方向(图像到文本,文本到图像)使用独立的多头注意力,并在输入和输出中分别应用 LayerNorm 的 v8 成功地完成了训练。这表明,在保留每个模态特性的同时进行信息交换是很重要的。
v10_1 (模态特异性 Q/K/V): 基于 v9 并引入每个模态专用 Q/K/V 变换的 v10_1 的训练不稳定。这可以解释为,模型复杂度增加了,过拟合的风险也增大了。
v10_2 (Cross-Gate): 在 v9 基础上添加跨模态门控机制的 v10_2 未能成功地完成训练。这可以看作是,门控机制没有恰当地控制两个模态之间的信息流动,反而阻碍了学习。可能是过早地限制了信息交换。
v10_3 (上下文层): 为每个模态添加独立上下文处理层的 v10_3 成功地完成了训练。这一层可以进一步提炼每个模态的特征,并提供额外的语境信息,从而有助于性能的提高。
v10_4 (多查询注意力): 保持查询(Q)独立,同时共享键(K)和值(V)的多查询注意力机制的 v10_4 成功地完成了训练。这可以看作是,减少参数数量的同时实现了高效的信息交换,从而提高了泛化性能。
v10_5 (分层多头): 引入三阶段分层结构,并在每个级别应用独立的多头注意力,然后通过权重融合的 v10_5 成功地完成了训练。这表明,逐步整合特征,并有效利用每个级别的信息,从而提高性能。
v10_6 (对比学习多头): 为对比学习添加独立投影层,并直接将相似度信息添加到原始特征中的 v10_6 的训练不稳定。这可能是由于相似度信息扭曲了原始特征,从而干扰了学习。
v11 (多查询 + 分层融合): 结合多查询注意力(v10_4)和分层多头(v10_5)的优势的 v11 成功地完成了训练。这意味着,利用参数效率和逐步特征整合这两个优点,实现了稳定的学习。
结论
通过这些移除实验,我们可以得出以下结论。 1. 标准化的重要性: 在输入特征上应用LayerNorm对于训练稳定性非常重要(v2)。 2. 残差连接的双面性: 残差连接是一个有用的机制,但在多模态学习的早期阶段,它可能会带来负面影响(v3)。过度保持原始特征会阻碍两个模态之间的交互学习。 3. 独立的特征变换: 在每个模态上应用独立的线性变换(投影)可以提高性能(v4)。 4. 多头注意力: 使用多头注意力时,每个头应该被独立配置以反映不同模态的特性(v7,v8)。 5. 适当的复杂度: 过度增加模型的复杂度可能会使训练变得不稳定(v10_1,v10_2,v10_6)。 6. 高效的机制: 多查询注意力(v10_4)和分层融合(v10_5)分别提供了参数效率和渐进特征整合的优势。 7. 最佳组合的重要性: 如v11所示,适当地组合有效的机制可以建立更稳定和性能更好的多模态学习模型。
这些去除实验对于理解多模态学习中每个组件的作用和重要性非常有用。进一步来说,它们为设计新的模型提供了重要的指导。通过系统地分析特定机制存在或不存在对性能的影响,可以了解哪些元素对多模态融合有效,以及哪种组合会带来最优结果。
设计更系统化的实验案例和项目框架可以使得大规模模型和各种机制的实验顺利进行。希望这能够帮助研究。
本节简要介绍了带来图像处理领域创新发展的视觉变换器(Vision Transformer,ViT)以及其扩展版ViT-22B和MAE。
2020年,谷歌研究团队通过《一张图片值16x16个词:大规模图像识别中的Transformer》这篇论文,将ViT介绍给世界。 ViT标志着长期主导图像处理领域的卷积神经网络(Convolutional Neural Network,CNN)时代的结束和基于Transformer的新时代的开始。
ViT的核心思想很简单:将一张图片分成多个小块(patch),然后像对待文本中的单词(token)一样处理每个patch。这样做可以将图像转换为一系列patch序列,并且Transformer可以接受这个序列作为输入进行处理。
ViT与CNN相比,有以下重要的不同之处:
ViT的出现完全改变了图像处理领域的研究方向。自ViT之后,以图像patch嵌入、注意力机制、大规模预训练为基础的各种后续研究大量涌现。
图像patch嵌入是ViT的第一步,过程是将二维图像转换为一维序列形式。在PyTorch中,torchvision.models.vision_transformer.PatchEmbed类负责这一角色。
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbed(nn.Module):
"""
Transforms a 2D image into a sequence of patch embeddings.
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
img_size: The size of the input image (assuming a square image)
patch_size: The patch size (assuming square patches)
in_chans: The number of input image channels (e.g., 3 for RGB images)
embed_dim: The dimension of the patch embedding vector
"""
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Transforms the input image into a sequence of patch embeddings.
Args:
x: Input image (shape: [batch_size, in_chans, img_size, img_size])
Returns:
Sequence of patch embeddings (shape: [batch_size, num_patches, embed_dim])
"""
x = self.projection(x) # [batch_size, embed_dim, num_patches_h, num_patches_w]
x = x.flatten(2) # [batch_size, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch_size, num_patches, embed_dim]
return xPatchEmbed 类的 __init__ 方法中最重要的部分是 self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)。这一行代码同时执行图像补丁划分和嵌入。
nn.Conv2d:PyTorch 中进行 2D 卷积运算的层。in_chans:输入图像的通道数(RGB 图像为 3)。embed_dim:输出嵌入向量的维度(ViT-Base 模型中为 768)。kernel_size=patch_size:设置卷积滤器(核)的大小与补丁大小相同。stride=patch_size:设置滤器在图像上移动的步长(stride)与补丁大小相同。通过将 kernel_size 和 stride 设置为 patch_size,卷积滤器以不重叠的方式,将图像划分为补丁,每个补丁精确地对应一个嵌入向量。每个卷积滤器压缩单个补丁的信息,生成一个嵌入向量。
PatchEmbed 类的 forward 方法通过 self.projection(x) 实际执行图像补丁嵌入。
self.projection(x):对输入图像 x(形状为 [batch_size, in_chans, img_size, img_size])应用 Conv2d 运算。输出的形状为 [batch_size, embed_dim, num_patches_h, num_patches_w],其中 num_patches_h 和 num_patches_w 分别是图像高度和宽度除以补丁大小后的值。x.flatten(2):将 Conv2d 输出平坦化为 [batch_size, embed_dim, num_patches] 形状,其中 num_patches 是总的补丁数量(即 num_patches_h * num_patches_w)。x.transpose(1, 2):交换张量维度,得到 [batch_size, num_patches, embed_dim] 形状。这是为了将每个补丁嵌入向量视为序列中的一个元素,以便输入到 transformer 编码器中。最终结果是,PatchEmbed 类划分图像为补丁,并通过线性变换(Linear Projection)将每个补丁转化为 embed_dim 维的向量,从而形成可以输入到 transformer 编码器的序列形式。
ViT 将图像划分为补丁,并将每个补丁视同文本中的单词一样输入到 transformer 中。但是,transformer 本身不能识别输入序列的顺序信息。因此,需要告知模型每个补丁对应于图像中的哪个位置。这正是 位姿编码(Positional Encoding) 的作用。
在 PyTorch 的 VisionTransformer 类中使用的是可学习的位姿嵌入,即在训练过程中同时优化每个补丁位置对应的唯一嵌入向量。
class VisionTransformer(nn.Module):
def __init__(self, ..., num_patches, embed_dim, ...):
super().__init__()
# ...
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # Class token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) # Positional embedding
self.pos_drop = nn.Dropout(p=drop_rate)
# ...
def _pos_embed(self, x):
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # Prepend class token
x = x + self.pos_embed # Add positional embedding
return self.pos_drop(x)
def forward(self, x):
x = self.patch_embed(x) # Patch embedding
x = self._pos_embed(x) # Add positional embedding
# ... (Transformer Encoder etc.) ...代码解释
self.pos_embed (可学习参数): 由 nn.Parameter 定义,会在训练过程中更新。其大小为 (1, num_patches + 1, embed_dim)。
num_patches + 1: 在图像 patches 之外,增加一个特殊的 类别标记 (class token) 的位置。embed_dim: 与 patch embedding 的维度相同。embed_dim。_pos_embed 方法:
x (patch embedding 序列) 的开头添加 self.cls_token。cls_token 会被复制(expand)以适应批次大小,从而对所有图像应用相同的操作。self.pos_embed 值。根据 PyTorch 的广播规则,self.pos_embed 的每个位置嵌入向量都会被自动添加到相应位置的所有 patch embedding 向量中。forward 方法: 在 forward 方法中,通过 self.patch_embed(x) 将图像转换为 patch embedding,然后调用 self._pos_embed(x) 添加位置嵌入。总结
ViT 使用可学习的位置嵌入,并将其添加到 patch embedding 上,以此向模型注入位置信息。位置嵌入会在模型训练过程中与其他权重一起被优化,从而能够以最适合数据的形式表示位置信息。
ViT (Vision Transformer) 是一种将图像处理为类似文本的方式来执行分类等视觉任务的模型。在 PyTorch 中,可以通过 torchvision.models.VisionTransformer 类使用 ViT 模型。
class VisionTransformer(nn.Module):
def __init__(self, ..., embed_dim, depth, num_heads, ...):
super().__init__()
self.patch_embed = PatchEmbed(...) # Image patch embedding
self.cls_token = nn.Parameter(...) # Class token
self.pos_embed = nn.Parameter(...) # Positional embedding
self.pos_drop = nn.Dropout(...)
self.blocks = nn.Sequential(*[
TransformerEncoderLayer(...) for _ in range(depth) # Transformer Encoder blocks
])
self.norm = nn.LayerNorm(embed_dim) # Layer Normalization
self.head = nn.Linear(embed_dim, num_classes) # Classification Head
def forward_features(self, x):
x = self.patch_embed(x) # 1. Patch embedding
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # 2. Prepend class token
x = x + self.pos_embed # 3. Add positional embedding
x = self.pos_drop(x)
x = self.blocks(x) # 4. Transformer Encoder
x = self.norm(x) # 5. LayerNorm
return x[:, 0] # 6. Return class token
def forward(self, x):
x = self.forward_features(x) # Feature extraction
x = self.head(x) # Classification
return xViT的核心组成部分:
PatchEmbed (patch嵌入): 将图像分割为多个小patch,然后将每个patch转换为固定维度的向量(嵌入)。(参见10.5.2节)cls_token (类别标记): 可学习参数,在patch嵌入序列的开头添加特殊标记。经过Transformer编码器后,该类别标记将包含代表图像整体信息(特征)的内容,并用于最终分类。pos_embed (位置嵌入): 表示每个patch(和类别标记)位置信息的可学习参数。由于Transformer无法自行感知输入序列的顺序,因此需要通过位置嵌入显式提供位置信息。(参见10.5.3节)blocks (Transformer编码器): 由多个 TransformerEncoderLayer 组成。
TransformerEncoderLayer: ViT的核心块,由多头自注意力(Multi-Head Self-Attention)和前馈网络(Feed-Forward Network,FFN)组成。
norm (层归一化): 对Transformer编码器的输出应用层归一化head (分类头): 接受Transformer编码器输出的类别标记作为输入,最后预测图像类别的全连接层。forward 方法(整个处理流程):
forward_features 方法:
self.patch_embed(x):将输入图像转换为patch嵌入序列。self.cls_token)。self.pos_embed)。self.blocks)。self.norm)。x[:, 0])。self.head(x):将 forward_features 返回的类别标记传递给分类头,以获得最终预测(分类)结果。总结:
ViT将图像分割为patch,并将每个patch输入Transformer编码器以提取图像整体特征。在此过程中,使用类别标记和位置嵌入同时考虑图像的全局信息和patch位置信息。最终,利用类别标记对图像进行分类。
让我们看一下如何使用ViT模型在CIFAR-10数据集上进行简单的训练。下面的代码使用PyTorch来训练ViT模型,并输出每个epoch的损失和准确率。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import vit_b_16 # Using vit_b_16 model as an example
from torch.utils.data import DataLoader
# Hyperparameter setup for a simple training run
num_epochs = 5
batch_size = 32
learning_rate = 1e-4
image_size = 224 # ViT input image size
num_classes = 10 # Number of classes in the CIFAR-10 dataset
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Data loading and preprocessing (using CIFAR-10 dataset)
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # Normalize with CIFAR-10 statistics
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Create ViT model (not using pretrained weights)
model = vit_b_16(pretrained=False, num_classes=num_classes).to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward and backward passes
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate statistics
running_loss += loss.item()
_, predicted = torch.max(outputs, 1) # Select the class with the highest probability
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# Print every 100 batches.
# if (i + 1) % 100 == 0:
# print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# Print epoch statistics
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct_predictions / total_samples * 100
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%')
print('Training finished!')100%|██████████| 170M/170M [00:21<00:00, 8.09MB/s]
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)Epoch [1/5], Step [100/1563], Loss: 2.1349
Epoch [1/5], Step [200/1563], Loss: 1.8978
Epoch [1/5], Step [300/1563], Loss: 1.9483
Epoch [1/5], Step [400/1563], Loss: 2.0783
Epoch [1/5], Step [500/1563], Loss: 1.7614
Epoch [1/5], Step [600/1563], Loss: 1.8051
Epoch [1/5], Step [700/1563], Loss: 1.7448
Epoch [1/5], Step [800/1563], Loss: 1.8347
Epoch [1/5], Step [900/1563], Loss: 1.8127
Epoch [1/5], Step [1000/1563], Loss: 1.7755
Epoch [1/5], Step [1100/1563], Loss: 1.6506
Epoch [1/5], Step [1200/1563], Loss: 1.7523
Epoch [1/5], Step [1300/1563], Loss: 1.5987
Epoch [1/5], Step [1400/1563], Loss: 1.6078
Epoch [1/5], Step [1500/1563], Loss: 1.7110
Epoch [1/5], Loss: 1.8429, Accuracy: 29.66%
Epoch [2/5], Step [100/1563], Loss: 1.4902
Epoch [2/5], Step [200/1563], Loss: 1.5161
Epoch [2/5], Step [300/1563], Loss: 1.4563
Epoch [2/5], Step [400/1563], Loss: 1.5858
Epoch [2/5], Step [500/1563], Loss: 1.6702
Epoch [2/5], Step [600/1563], Loss: 1.5833
Epoch [2/5], Step [700/1563], Loss: 1.4790
Epoch [2/5], Step [800/1563], Loss: 1.6507
Epoch [2/5], Step [900/1563], Loss: 1.6017
Epoch [2/5], Step [1000/1563], Loss: 1.5102
Epoch [2/5], Step [1100/1563], Loss: 1.2946
Epoch [2/5], Step [1200/1563], Loss: 1.3225
Epoch [2/5], Step [1300/1563], Loss: 1.9922
Epoch [2/5], Step [1400/1563], Loss: 1.3685
Epoch [2/5], Step [1500/1563], Loss: 1.4852
Epoch [2/5], Loss: 1.5410, Accuracy: 42.69%
Epoch [3/5], Step [100/1563], Loss: 1.2692
Epoch [3/5], Step [200/1563], Loss: 1.1648
Epoch [3/5], Step [300/1563], Loss: 1.2412
Epoch [3/5], Step [400/1563], Loss: 1.6217
Epoch [3/5], Step [500/1563], Loss: 1.3776
Epoch [3/5], Step [600/1563], Loss: 1.2591
Epoch [3/5], Step [700/1563], Loss: 1.4333
Epoch [3/5], Step [800/1563], Loss: 1.3301
Epoch [3/5], Step [900/1563], Loss: 1.3536
Epoch [3/5], Step [1000/1563], Loss: 1.4488
Epoch [3/5], Step [1100/1563], Loss: 1.3179
Epoch [3/5], Step [1200/1563], Loss: 1.0684
Epoch [3/5], Step [1300/1563], Loss: 1.6526
Epoch [3/5], Step [1400/1563], Loss: 1.1815
Epoch [3/5], Step [1500/1563], Loss: 1.3683
Epoch [3/5], Loss: 1.3836, Accuracy: 49.23%
Epoch [4/5], Step [100/1563], Loss: 1.2601
Epoch [4/5], Step [200/1563], Loss: 1.3277
Epoch [4/5], Step [300/1563], Loss: 1.1337
Epoch [4/5], Step [400/1563], Loss: 1.2273
Epoch [4/5], Step [500/1563], Loss: 1.7351
Epoch [4/5], Step [600/1563], Loss: 1.3826
Epoch [4/5], Step [700/1563], Loss: 1.2639
Epoch [4/5], Step [800/1563], Loss: 1.5757
Epoch [4/5], Step [900/1563], Loss: 1.0702
Epoch [4/5], Step [1000/1563], Loss: 1.3986
Epoch [4/5], Step [1100/1563], Loss: 1.1105
Epoch [4/5], Step [1200/1563], Loss: 1.2621
Epoch [4/5], Step [1300/1563], Loss: 1.4261
Epoch [4/5], Step [1400/1563], Loss: 1.3028
Epoch [4/5], Step [1500/1563], Loss: 1.9051
Epoch [4/5], Loss: 1.2850, Accuracy: 52.98%
Epoch [5/5], Step [100/1563], Loss: 0.9517
Epoch [5/5], Step [200/1563], Loss: 0.9844
Epoch [5/5], Step [300/1563], Loss: 1.2391
Epoch [5/5], Step [400/1563], Loss: 1.3588
Epoch [5/5], Step [500/1563], Loss: 0.9441
Epoch [5/5], Step [600/1563], Loss: 1.1711
Epoch [5/5], Step [700/1563], Loss: 1.1687
Epoch [5/5], Step [800/1563], Loss: 1.0097
Epoch [5/5], Step [900/1563], Loss: 0.9899
Epoch [5/5], Step [1000/1563], Loss: 1.3289
Epoch [5/5], Step [1100/1563], Loss: 1.5510
Epoch [5/5], Step [1200/1563], Loss: 0.9139
Epoch [5/5], Step [1300/1563], Loss: 0.9221
Epoch [5/5], Step [1400/1563], Loss: 1.3378
Epoch [5/5], Step [1500/1563], Loss: 1.1785
Epoch [5/5], Loss: 1.2116, Accuracy: 55.78%
Training finished!此代码是用于展示ViT模型工作原理的简单示例。实际上,ViT是在像ImageNet这样的大型数据集上进行预训练(pre-training)的,然后针对特定任务(例如CIFAR-10分类)进行微调(fine-tuning),这样使用时会表现出更好的性能。在这里,我们仅仅检查它是否可以简单地进行训练。
ViT的意义和影响
ViT在图像分类任务中展示了超越CNN的性能,引起了计算机视觉领域的巨大反响。特别是,当使用JFT-300M这样的超过3亿张图片的大型数据集进行预训练时,它表现出了真正的价值。这给我们带来了两个重要的启示。
可扩展性(Scalability): ViT展示了随着数据集大小的增加,其性能会持续提高的卓越可扩展性。这与基于CNN的模型在一定规模以上的数据集中,性能会停滞甚至下降的现象形成对比。ViT的这一特点为我们打开了未来利用更多数据构建更强大视觉模型的可能性。
Transformer的通用性: ViT证明了广泛用于自然语言处理(NLP)领域的Transformer架构在图像处理领域也是有效的。这成为研究能够使用一种架构处理多种模态(包括文本、图像、语音等)的多模态模型的重要起点。
ViT的成功为之后CLIP(对比语言-图像预训练)等多模态模型的开发提供了重要基础。CLIP通过结合ViT的图像编码器和基于Transformer的文本编码器,学习将图像和文本表示在一个统一的空间中。这样,使得生成图像的文本描述或基于文本描述搜索图像等各种应用成为可能。
严格指令:
$...$ 或 $$...$$ 包围的 LaTeX 数学表达式。将它们保持为原样。|、连字符 -、冒号 :)保持原样。仅翻译表格单元格内的文本内容。Google Research 团队提出的并训练的 ViT-22B 在图像分类中超越了 CNN 的表现,同时也引起了计算机视觉领域的巨大反响。ViT-22B 证明了,模型和数据的尺寸扩大是提高性能的一个关键因素。凭借其220亿个参数和数十亿张图像组成的超大规模数据集,ViT-22B 达到了以前难以想象的性能水平,并开启了视觉 AI 的新纪元。
诞生背景:缩放法则和大型语言模型的成功
ViT-22B 的出现与自然语言处理(NLP)领域中大型语言模型(Large Language Model, LLM)的惊人成功密切相关。像 GPT-3 这样的 LLM 表明,随着模型尺寸(参数数量)和数据量的增加,其性能也会持续提高,这遵循 缩放法则(scaling law) 。这种趋势传播了“更大即更好”的信念,并促使视觉领域进行类似的尝试。
由于 ViT 基于Transformer架构,因此可以轻松应用LLM中验证的缩放策略。ViT 将图像patches处理为文本tokens,这意味着可以在不大幅度改变模型结构的情况下增加参数数量并使用更多数据进行训练。
ViT-22B 的结构和特点
ViT-22B基本上遵循了 ViT 的架构,但在 规模 方面有着根本的不同。
巨大的模型尺寸: 拥有220亿个参数的ViT-22B与ViT-Base(8600万个)、ViT-Large(3.7亿个)和ViT-Huge(6.32亿个)相比具有压倒性的规模优势。这意味着模型可以捕捉到更加复杂和细微的图像特征,并内含更多的知识。
超大规模数据集: ViT-22B是在数十亿张图像组成的 非公开 数据集(如JFT-4B)上训练的。如此大量的数据对于模型实现最佳的泛化性能和全面的学习各种图像分布至关重要。
提升的性能: ViT-22B在图像分类、物体检测、图像分割等多个视觉基准测试中展示出了超越现有任何模型的最优性能(SOTA, State-Of-The-Art)。这清楚地表明了模型尺寸和数据量对性能的积极影响。
ViT-22B 训练的困难和启示
训练像 ViT-22B 这样的超大规模模型对于一般的研究环境来说几乎是不可能的。它需要数百到数千个GPU或TPU这样的高昂特殊硬件,训练时间也可能长达几周甚至几个月。此外,存储和处理大量数据所需的基础设施建设也是一个巨大的挑战。
ViT-22B 的出现证实了 ViT 架构的可扩展性,但同时也提出了关于 效率 的思考。随着模型尺寸的增长,性能会提高,但是训练和推理所需的计算资源和能耗也会呈几何级数增加。因此,未来研究将朝着在保持性能的同时提高效率的方向进行。 Meta AI (Facebook AI Research,FAIR)团队提出的MAE(Masked Autoencoder)是一种利用无标签的大规模图像数据集来学习强大图像表示的自监督学习方法。基于ViT的MAE通过随机遮挡图像的大部分并训练模型恢复被遮挡的部分。MAE v3是MAE的最新版本,通过多种改进进一步提高了性能和效率。
MAE的工作原理
MAE的核心思想是让模型像人类解决“填空”问题一样,只需看到图像的一部分信息就能理解和恢复整个图像。
输入图像的随机遮挡: 随机遮挡输入图像的大部分(例如75%)。此时,以图像补丁为单位进行遮挡。
编码(Encoding): 只将未被遮挡的补丁,即可见的补丁输入到ViT编码器中,提取特征向量。
解码(Decoding): 使用编码器的输出(可见补丁的特征)和被遮挡的补丁的信息共同恢复原始图像。此时,解码器采用轻量级Transformer块以提高计算效率。
恢复损失(Reconstruction Loss): 计算恢复图像与原图之间的像素级差异(例如均方误差,MSE),并训练模型(编码器和解码器)以最小化这种差异。
MAE v3的结构改进
MAE v3通过以下主要改进相比之前版本实现了更好的性能和效率:
改进的遮挡策略: 초기MAE简单地随机遮挡补丁,而MAE v3使用更为精致的遮挡策略。例如,图像的有意义区域(物体边界等)可以被更好地保留,或者不同大小的补丁可以被遮挡。
优化的编码器-解码器结构:
MAE的优势和意义
MAE具有以下优势,在自监督学习领域受到关注:
无需标签的学习: MAE可以利用无标签的大规模图像数据集进行预训练。这节省了手动创建标签的成本和时间,并允许使用更多的数据。
强大的表示学习: MAE通过恢复被遮挡的图像,学会理解图像的结构、意义和上下文。这种能力有助于在图像分类、物体检测、分割等多种下游任务中实现良好的性能。
迁移学习的便利性: 用MAE预训练的模型可以通过微调应用于各种任务。这使得即使在标签不足的任务中也能获得良好的性能。 MAE通过“填空”这一直觉的想法,提出了一种即使没有标签也能学习强大图像表示的有效方法。 MAE v3进一步发展了这种MAE的优势,实现了更高的性能和效率,并推动着自监督学习研究的进展。
2021年,OpenAI通过论文“Learning Transferable Visual Models From Natural Language Supervision”发布了 CLIP(Contrastive Language-Image Pre-training) 模型。CLIP通过学习将图像和文本这两种不同的模态表示到一个共享空间中,从而在多模态学习领域带来了创新性的进展。
CLIP的核心是图像编码器(Image Encoder)和文本编码器(Text Encoder),这两种独立的编码器构成了双编码器结构。
这两个编码器通过对比学习进行训练。
CLIP 训练的核心:对比学习(Contrastive Learning)
CLIP 训练的核心是使用大规模图像-文本对数据集的对比学习。
代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CLIP(nn.Module):
def __init__(self, image_encoder, text_encoder, embed_dim):
super().__init__()
self.image_encoder = image_encoder
self.text_encoder = text_encoder
self.image_projection = nn.Linear(image_encoder.output_dim, embed_dim)
self.text_projection = nn.Linear(text_encoder.output_dim, embed_dim)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) # Learnable scale parameter
def forward(self, images, texts):
# 1. Image encoding
image_features = self.image_encoder(images) # [batch_size, image_encoder.output_dim]
image_embeddings = self.image_projection(image_features) # [batch_size, embed_dim]
image_embeddings = F.normalize(image_embeddings, dim=-1) # L2 normalization
# 2. Text encoding
text_features = self.text_encoder(texts) # [batch_size, text_encoder.output_dim]
text_embeddings = self.text_projection(text_features) # [batch_size, embed_dim]
text_embeddings = F.normalize(text_embeddings, dim=-1) # L2 normalization
# 3. Similarity calculation
logits_per_image = self.logit_scale.exp() * image_embeddings @ text_embeddings.t() # [batch_size, batch_size]
logits_per_text = logits_per_image.t() # [batch_size, batch_size]
return logits_per_image, logits_per_text
def contrastive_loss(logits_per_image, logits_per_text):
"""
Calculates the Contrastive Loss
"""
batch_size = logits_per_image.shape[0]
labels = torch.arange(batch_size).to(logits_per_image.device) # Correct labels (diagonal: same pair)
loss_i = F.cross_entropy(logits_per_image, labels) # Loss based on image
loss_t = F.cross_entropy(logits_per_text, labels) # Loss based on text
return (loss_i + loss_t) / 2 # Average lossCLIP的图像编码器将输入图像转换为固定维度的嵌入向量。初始CLIP论文中,实验了ResNet和ViT(Vision Transformer)。
实验结果表明,基于ViT的编码器比基于ResNet的编码器具有更好的性能。特别是,当模型和数据大小增加时,ViT的性能提升更加显著。
CLIP的文本编码器将输入文本转换为与图像编码器相同维度的嵌入向量。初始CLIP论文中,使用了基于Transformer的文本编码器。
CLIP的一个主要特征是其在各种图像分类任务中表现出色的零样本(zero-shot)传递能力,无需额外的微调。
零样本传递的原因
CLIP通过对大规模图像-文本对数据集进行对比学习,在同一个语义空间中表示图像和文本。因此,CLIP能够理解图像和文本之间的语义相关性。
零样本分类过程
零样本传递的意义
零样本传递意味着模型可以在没有任何额外训练或微调的情况下应用于新的、从未见过的类别或任务。这与传统的监督学习方法不同,后者需要特定任务的标记数据。零样本传递的核心是灵活性。例如,如果图像分类模型仅使用“猫”和“狗”类别的数据进行训练,但提供了“长颈鹿”或“大象”的自然语言描述,即使没有这些类别的训练数据,模型也可以正确地对新类别的图像进行分类。这种能力是零样本传递最大的优势。 此外,Zero-shot迁移提供了通用性。不仅限于图像分类,还可以应用于图像搜索、图像字幕、对象检测(object detection)、视觉问答(Visual Question Answering, VQA)等多种多模态任务。例如,在图像搜索系统中输入“红色跑车”这样的文本查询,模型就可以在数据库中找到对应的图像。这是因为模型理解了图像和文本之间的语义联系。这样,一個模型可以应用于多种任务,这大大节省了时间和资源,并提高了人工智能系统的利用率。
CLIP的影响
CLIP通过零样本迁移能力提出了多模态学习的新可能性。在此基础上,后续研究也在不断进行,像DALL-E、Stable Diffusion这样的图像生成模型,以及GPT-4V这样的大规模多模态模型的开发,都受到了CLIP思想的重大影响。
对比学习是一种强大的方法,可以在无标签数据中学习表示。特别是在连接不同模态(如图像和文本)的多模态学习中,它表现出色的成绩。本深度潜水中,我们将深入分析对比学习的基本原理、各种方法,以及基于对比学习连接图像和文本的开创性模型CLIP(对比语言-图像预训练)。
对比学习的核心思想是学习表示,使得相似的样本对在嵌入空间中靠近,而不相似的样本对则远离。
对比学习通常遵循以下步骤:
已经提出了多种对比损失函数,以下是一些代表性的例子:
InfoNCE损失(Noise Contrastive Estimation):与交叉熵损失类似,它最大化了正样本对的softmax概率。
\(L = -\log \frac{\exp(\text{sim}(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k) / \tau)}\)
NT-Xent损失(Normalized Temperature-scaled Cross Entropy Loss):InfoNCE损失的变体,由SimCLR论文提出。
三元组损失(Triplet Loss):使用锚点、正样本和负样本,训练模型使得锚点与正样本之间的距离小于锚点与负样本之间的距离。
\(L = \max(0, d(a, p) - d(a, n) + m)\)
\(a\): 锚点
CLIP是OpenAI开发的模型,它使用对比学习来学习强大的多模态表示,以连接图像和文本。
* 在批处理中,每个图像都有一个正文本和(N-1)个负文本。
* 同样,每个文本都有一个正图像和(N-1)个负图像。对比学习是一种利用无标签数据来学习强大表达的有效方法。特别是CLIP成功地将对比学习应用于多模态学习,开辟了图像和文本连接的新天地。未来,对比学习和CLIP很可能在各个领域得到广泛应用。
参考文献: * 陈天奇、科恩布利斯、诺鲁兹、欣顿(2020)。一种简单的视觉表示对比学习框架。机器学习国际会议。PMLR。 * 拉德福、金正文、霍拉西、拉梅什、高戈、阿加瓦尔等人(2021)。从自然语言监督中学习可迁移的视觉模型。机器学习国际会议。PMLR。 * 何凯明、樊航、吴云峰、谢世光、吉尔希克(2020)。无监督视觉表示学习中的动量对比。在IEEE/CVF计算机视觉与模式识别会议论文集(第9729-9738页)。 * 格里尔、斯特鲁布、阿尔切、塔勒克、里什蒙、布查茨卡娅等人(2020)。自举你的潜在表示:一种新的自监督学习方法。神经信息处理系统进展,33,21271-21284。
基本问题
应用问题
blip-image-captioning-base模型)。深化问题
VQA模型结构:
graph LR
subgraph VQA Model
A[图像] --> B(图像编码器 - CNN)
C[问题文本] --> D(文本编码器 - RNN/Transformer)
B --> E(融合模块)
D --> E
E --> F(解码器 - RNN/Transformer)
F --> G(答案)
endCLIP训练方式及优势:
Hugging Face Transformers 图片字幕代码:
from transformers import pipeline
captioner = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning") # 或 "blip-image-captioning-base"
image_path = "path/to/your/image.jpg" # 图片文件路径
caption = captioner(image_path)[0]['generated_text']
print(caption)多模态融合方法:
跨模态注意力:
基于文本的图片生成模型(DALL-E、Stable Diffusion等):
CLIP (从自然语言监督中学习可迁移的视觉模型):一种将图像和文本连接起来的多模态表示学习方法,CLIP原始论文。 https://arxiv.org/abs/2103.00020
ViT (一张图片值16x16个词:大规模图像识别中的Transformer):仅使用Transformer结构而无需CNN,在图像分类中表现出色的ViT原始论文。 https://arxiv.org/abs/2010.11929
DALL-E (零样本文本到图像生成):基于文本描述生成图像的DALL-E模型论文。 https://arxiv.org/abs/2102.12092
MAE (掩蔽自动编码器是可扩展的视觉学习者):通过遮挡图像的一部分并恢复来学习视觉表示的MAE论文。 https://arxiv.org/abs/2111.06377
视觉问答 (VQA):早期VQA研究之一,提出VQA数据集和基线模型。 https://arxiv.org/abs/1505.00468
展示、关注和讲述 (具有视觉注意力的神经图像字幕生成):首次将注意力机制引入图像字幕生成的论文。 https://arxiv.org/abs/1502.03044
多模态机器学习:调查和分类法:对多模态机器学习的全面综述论文。 https://arxiv.org/abs/1705.09406
多模态深度学习教程,Jiquan Ngiam:NeurIPS 2011的多模态深度学习教程(视频)。 https://www.youtube.com/watch?v=cR_ACqfF-bY&list=PL_45CaSOtPzL-HWxMcnr02KvmP9Gq-xdb
CMU Multimodal Machine Learning Course (11-777, Spring 2023), Louis-Philippe Morency: 卡内基梅隆大学多模态机器学习课程资料。 https://cmu-multicomp-lab.github.io/mmml-course/spring2023/
A Comprehensive Survey on Deep Multimodal Learning: 2022年多模态深度学习survey论文。 https://arxiv.org/abs/2204.11984
arXiv: 最新多模态学习研究论文搜索。使用”multimodal learning”, “vision-language”等关键词。 https://arxiv.org/
Hugging Face Transformers Multimodal Documentation: Hugging Face Transformers库的多模态模型文档。 https://huggingface.co/docs/transformers/main/en/model_doc/auto#multimodal-models
严格指令:
$...$ 或 $$...$$ 围起来的 LaTeX 数学表达式。保持它们完全不变。|、连字符 -、冒号 :)完全不变。仅翻译表格单元格内的文本内容。